32. Incorrect Models#
GPU
This lecture was built using a machine with access to a GPU — although it will also run without one.
Google Colab has a free tier with GPUs that you can access as follows:
Click on the “play” icon top right
Select Colab
Set the runtime environment to include a GPU
!pip install numpyro jax
32.1. Overview#
This is a sequel to this quantecon lecture.
We discuss two ways to create a compound lottery and their consequences.
A compound lottery can be said to create a mixture distribution.
Our two ways of constructing a compound lottery will differ in their timing.
in one, mixing between two possible probability distributions will occur once and all at the beginning of time
in the other, mixing between the same two possible probability distributions will occur each period
The statistical setting is close but not identical to the problem studied in that quantecon lecture.
In that lecture, there were two i.i.d. processes that could possibly govern successive draws of a non-negative random variable \(W\).
Nature decided once and for all whether to make a sequence of IID draws from either \( f \) or from \( g \).
That lecture studied an agent who knew both \(f\) and \(g\) but did not know which distribution nature chose at time \(-1\).
The agent represented that ignorance by assuming that nature had chosen \(f\) or \(g\) by flipping an unfair coin that put probability \(\pi_{-1}\) on probability distribution \(f\).
That assumption allowed the agent to construct a subjective joint probability distribution over the random sequence \(\{W_t\}_{t=0}^\infty\).
We studied how the agent would then use the laws of conditional probability and an observed history \(w^t =\{w_s\}_{s=0}^t\) to form
However, in the setting of this lecture, that rule imputes to the agent an incorrect model.
The reason is that now the wage sequence is actually described by a different statistical model.
Thus, we change the quantecon lecture specification in the following way.
Now, each period \(t \geq 0\), nature flips a possibly unfair coin that comes up \(f\) with probability \(\alpha\) and \(g\) with probability \(1 -\alpha\).
Thus, nature perpetually draws from the mixture distribution with c.d.f.
We’ll study two agents who try to learn about the wage process, but who use different statistical models.
Both types of agent know \(f\) and \(g\) but neither knows \(\alpha\).
Our first type of agent erroneously thinks that at time \(-1\) nature once and for all chose \(f\) or \(g\) and thereafter permanently draws from that distribution.
Our second type of agent knows, correctly, that nature mixes \(f\) and \(g\) with mixing probability \(\alpha \in (0,1)\) each period, though the agent doesn’t know the mixing parameter.
Our first type of agent applies the learning algorithm described in this quantecon lecture.
In the context of the statistical model that prevailed in that lecture, that was a good learning algorithm and it enabled the Bayesian learner eventually to learn the distribution that nature had drawn at time \(-1\).
This is because the agent’s statistical model was correct in the sense of being aligned with the data generating process.
But in the present context, our type 1 decision maker’s model is incorrect because the model \(h\) that actually generates the data is neither \(f\) nor \(g\) and so is beyond the support of the models that the agent thinks are possible.
Nevertheless, we’ll see that our first type of agent muddles through and eventually learns something interesting and useful, even though it is not true.
Instead, it turns out that our type 1 agent who is armed with a wrong statistical model ends up learning whichever probability distribution, \(f\) or \(g\), is in a special sense closest to the \(h\) that actually generates the data.
We’ll tell the sense in which it is closest.
Our second type of agent understands that nature mixes between \(f\) and \(g\) each period with a fixed mixing probability \(\alpha\).
But the agent doesn’t know \(\alpha\).
The agent sets out to learn \(\alpha\) using Bayes’ law applied to his model.
His model is correct in the sense that it includes the actual data generating process \(h\) as a possible distribution.
In this lecture, we’ll learn about
how nature can mix between two distributions \(f\) and \(g\) to create a new distribution \(h\).
The Kullback-Leibler statistical divergence https://en.wikipedia.org/wiki/Kullback–Leibler_divergence that governs statistical learning under an incorrect statistical model
A useful Python function
numpy.searchsortedthat, in conjunction with a uniform random number generator, can be used to sample from an arbitrary distribution
As usual, we’ll start by importing some Python tools.
import matplotlib.pyplot as plt
import numpy as np
from numba import vectorize, jit
from math import gamma
import pandas as pd
import scipy.stats as sp
from scipy.integrate import quad
import seaborn as sns
colors = sns.color_palette()
import numpyro
import numpyro.distributions as dist
from numpyro.infer import MCMC, NUTS
import jax.numpy as jnp
from jax import random
np.random.seed(142857)
@jit
def set_seed():
np.random.seed(142857)
set_seed()
Let’s use Python to generate two beta distributions
# Parameters in the two beta distributions.
F_a, F_b = 1, 1
G_a, G_b = 3, 1.2
@vectorize
def p(x, a, b):
r = gamma(a + b) / (gamma(a) * gamma(b))
return r * x** (a-1) * (1 - x) ** (b-1)
# The two density functions.
f = jit(lambda x: p(x, F_a, F_b))
g = jit(lambda x: p(x, G_a, G_b))
@jit
def simulate(a, b, T=50, N=500):
'''
Generate N sets of T observations of the likelihood ratio,
return as N x T matrix.
'''
l_arr = np.empty((N, T))
for i in range(N):
for j in range(T):
w = np.random.beta(a, b)
l_arr[i, j] = f(w) / g(w)
return l_arr
We’ll also use the following Python code to prepare some informative simulations
l_arr_g = simulate(G_a, G_b, N=50000)
l_seq_g = np.cumprod(l_arr_g, axis=1)
l_arr_f = simulate(F_a, F_b, N=50000)
l_seq_f = np.cumprod(l_arr_f, axis=1)
32.2. Sampling from Compound Lottery \(H\)#
We implement two methods to draw samples from our mixture model \(\alpha F + (1-\alpha) G\).
We’ll generate samples using each of them and verify that they match well.
Here is pseudo code for a direct “method 1” for drawing from our compound lottery:
Step one:
use the numpy.random.choice function to flip an unfair coin that selects distribution \(F\) with prob \(\alpha\) and \(G\) with prob \(1 -\alpha\)
Step two:
draw from either \(F\) or \(G\), as determined by the coin flip.
Step three:
put the first two steps in a big loop and do them for each realization of \(w\)
Our second method uses a uniform distribution and the following fact that we also described and used in the quantecon lecture https://python.quantecon.org/prob_matrix.html:
If a random variable \(X\) has c.d.f. \(F\), then a random variable \(F^{-1}(U)\) also has c.d.f. \(F\), where \(U\) is a uniform random variable on \([0,1]\).
In other words, if \(X \sim F(x)\) we can generate a random sample from \(F\) by drawing a random sample from a uniform distribution on \([0,1]\) and computing \(F^{-1}(U)\).
We’ll use this fact
in conjunction with the numpy.searchsorted command to sample from \(H\) directly.
See https://numpy.org/doc/stable/reference/generated/numpy.searchsorted.html for the
searchsorted function.
See the Mr. P Solver video on Monte Carlo simulation to see other applications of this powerful trick.
In the Python code below, we’ll use both of our methods and confirm that each of them does a good job of sampling from our target mixture distribution.
@jit
def draw_lottery(p, N):
"Draw from the compound lottery directly."
draws = []
for i in range(0, N):
if np.random.rand()<=p:
draws.append(np.random.beta(F_a, F_b))
else:
draws.append(np.random.beta(G_a, G_b))
return np.array(draws)
def draw_lottery_MC(p, N):
"Draw from the compound lottery using the Monte Carlo trick."
xs = np.linspace(1e-8,1-(1e-8),10000)
CDF = p*sp.beta.cdf(xs, F_a, F_b) + (1-p)*sp.beta.cdf(xs, G_a, G_b)
Us = np.random.rand(N)
draws = xs[np.searchsorted(CDF[:-1], Us)]
return draws
# verify
N = 100000
α = 0.0
sample1 = draw_lottery(α, N)
sample2 = draw_lottery_MC(α, N)
# plot draws and density function
plt.hist(sample1, 50, density=True, alpha=0.5, label='direct draws')
plt.hist(sample2, 50, density=True, alpha=0.5, label='MC draws')
xs = np.linspace(0,1,1000)
plt.plot(xs, α*f(xs)+(1-α)*g(xs), color='red', label='density')
plt.legend()
plt.show()
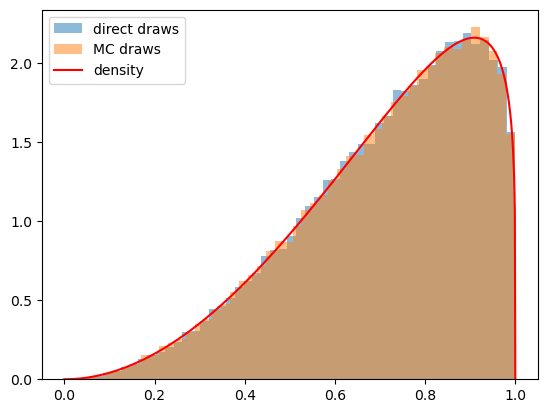
32.3. Type 1 Agent#
We’ll now study what our type 1 agent learns
Remember that our type 1 agent uses the wrong statistical model, thinking that nature mixed between \(f\) and \(g\) once and for all at time \(-1\).
The type 1 agent thus uses the learning algorithm studied in this quantecon lecture.
We’ll briefly review that learning algorithm now.
Let \( \pi_t \) be a Bayesian posterior defined as
The likelihood ratio process plays a principal role in the formula that governs the evolution of the posterior probability \( \pi_t \), an instance of Bayes’ Law.
Bayes’ law implies that \( \{\pi_t\} \) obeys the recursion
with \( \pi_{0} \) being a Bayesian prior probability that \( q = f \), i.e., a personal or subjective belief about \( q \) based on our having seen no data.
Below we define a Python function that updates belief \( \pi \) using likelihood ratio \( \ell \) according to recursion (32.1)
@jit
def update(π, l):
"Update π using likelihood l"
# Update belief
π = π * l / (π * l + 1 - π)
return π
Formula (32.1) can be generalized by iterating on it and thereby deriving an expression for the time \( t \) posterior \( \pi_{t+1} \) as a function of the time \( 0 \) prior \( \pi_0 \) and the likelihood ratio process \( L(w^{t+1}) \) at time \( t \).
To begin, notice that the updating rule
implies
Therefore
Since \( \pi_{0}\in\left(0,1\right) \) and \( L\left(w^{t+1}\right)>0 \), we can verify that \( \pi_{t+1}\in\left(0,1\right) \).
After rearranging the preceding equation, we can express \( \pi_{t+1} \) as a function of \( L\left(w^{t+1}\right) \), the likelihood ratio process at \( t+1 \), and the initial prior \( \pi_{0} \)
Formula (32.2) generalizes formula (32.1).
Formula (32.2) can be regarded as a one step revision of prior probability \( \pi_0 \) after seeing the batch of data \( \left\{ w_{i}\right\} _{i=1}^{t+1} \).
32.4. What a type 1 Agent Learns when Mixture \(H\) Generates Data#
We now study what happens when the mixture distribution \(h;\alpha\) truly generated the data each period.
The sequence \(\pi_t\) continues to converge, despite the agent’s misspecified model, and the limit is either \(0\) or \(1\).
This is true even though in truth nature always mixes between \(f\) and \(g\).
After verifying that claim about possible limit points of \(\pi_t\) sequences, we’ll drill down and study what fundamental force determines the limiting value of \(\pi_t\).
Let’s set a value of \(\alpha\) and then watch how \(\pi_t\) evolves.
def simulate_mixed(α, T=50, N=500):
"""
Generate N sets of T observations of the likelihood ratio,
return as N x T matrix, when the true density is mixed h;α
"""
w_s = draw_lottery(α, N*T).reshape(N, T)
l_arr = f(w_s) / g(w_s)
return l_arr
def plot_π_seq(α, π1=0.2, π2=0.8, T=200):
"""
Compute and plot π_seq and the log likelihood ratio process
when the mixed distribution governs the data.
"""
l_arr_mixed = simulate_mixed(α, T=T, N=50)
l_seq_mixed = np.cumprod(l_arr_mixed, axis=1)
T = l_arr_mixed.shape[1]
π_seq_mixed = np.empty((2, T+1))
π_seq_mixed[:, 0] = π1, π2
for t in range(T):
for i in range(2):
π_seq_mixed[i, t+1] = update(π_seq_mixed[i, t], l_arr_mixed[0, t])
# plot
fig, ax1 = plt.subplots()
for i in range(2):
ax1.plot(range(T+1), π_seq_mixed[i, :], label=rf"$\pi_0$={π_seq_mixed[i, 0]}")
ax1.plot(np.nan, np.nan, '--', color='b', label='Log likelihood ratio process')
ax1.set_ylabel(r"$\pi_t$")
ax1.set_xlabel("t")
ax1.legend()
ax1.set_title("when $\\alpha F + (1-\\alpha)G$ governs data")
ax2 = ax1.twinx()
ax2.plot(range(1, T+1), np.log(l_seq_mixed[0, :]), '--', color='b')
ax2.set_ylabel("$log(L(w^{t}))$")
plt.show()
plot_π_seq(α = 0.6)
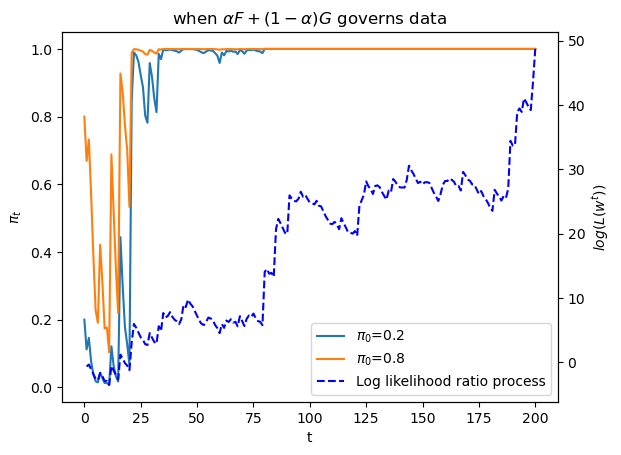
The above graph shows a sample path of the log likelihood ratio process as the blue dotted line, together with sample paths of \(\pi_t\) that start from two distinct initial conditions.
Let’s see what happens when we change \(\alpha\)
plot_π_seq(α = 0.2)
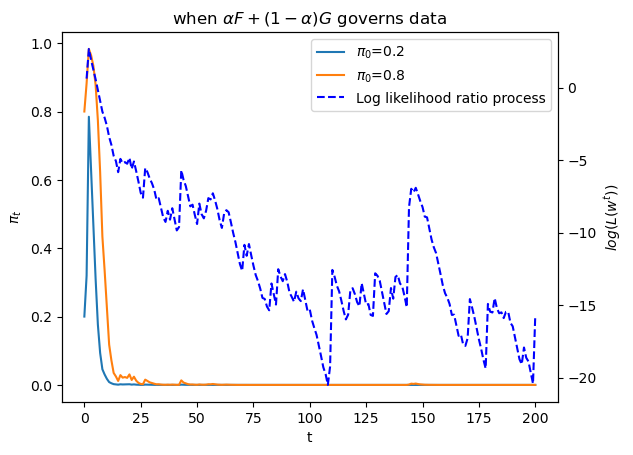
Evidently, \(\alpha\) is having a big effect on the destination of \(\pi_t\) as \(t \rightarrow + \infty\)
32.5. Kullback-Leibler Divergence Governs Limit of \(\pi_t\)#
To understand what determines whether the limit point of \(\pi_t\) is \(0\) or \(1\) and how the answer depends on the true value of the mixing probability \(\alpha \in (0,1) \) that generates
we shall compute the following two Kullback-Leibler divergences
and
We shall plot both of these functions against \(\alpha\) as we use \(\alpha\) to vary \(h(w) = h(w|\alpha)\).
The limit of \(\pi_t\) is determined by
The only possible limits are \(0\) and \(1\).
As \(t \rightarrow +\infty\), \(\pi_t\) goes to one if and only if \(KL_f < KL_g\)
@vectorize
def KL_g(α):
"Compute the KL divergence KL(h, g)."
err = 1e-8 # to avoid 0 at end points
ws = np.linspace(err, 1-err, 10000)
gs, fs = g(ws), f(ws)
hs = α*fs + (1-α)*gs
return np.sum(np.log(hs/gs)*hs)/10000
@vectorize
def KL_f(α):
"Compute the KL divergence KL(h, f)."
err = 1e-8 # to avoid 0 at end points
ws = np.linspace(err, 1-err, 10000)
gs, fs = g(ws), f(ws)
hs = α*fs + (1-α)*gs
return np.sum(np.log(hs/fs)*hs)/10000
# compute KL using quad in Scipy
def KL_g_quad(α):
"Compute the KL divergence KL(h, g) using scipy.integrate."
h = lambda x: α*f(x) + (1-α)*g(x)
return quad(lambda x: h(x) * np.log(h(x)/g(x)), 0, 1)[0]
def KL_f_quad(α):
"Compute the KL divergence KL(h, f) using scipy.integrate."
h = lambda x: α*f(x) + (1-α)*g(x)
return quad(lambda x: h(x) * np.log(h(x)/f(x)), 0, 1)[0]
# vectorize
KL_g_quad_v = np.vectorize(KL_g_quad)
KL_f_quad_v = np.vectorize(KL_f_quad)
# Let us find the limit point
def π_lim(α, T=5000, π_0=0.4):
"Find limit of π sequence."
π_seq = np.zeros(T+1)
π_seq[0] = π_0
l_arr = simulate_mixed(α, T, N=1)[0]
for t in range(T):
π_seq[t+1] = update(π_seq[t], l_arr[t])
return π_seq[-1]
π_lim_v = np.vectorize(π_lim)
Let us first plot the KL divergences \(KL_g\left(\alpha\right), KL_f\left(\alpha\right)\) for each \(\alpha\).
α_arr = np.linspace(0, 1, 100)
KL_g_arr = KL_g(α_arr)
KL_f_arr = KL_f(α_arr)
fig, ax = plt.subplots(1, figsize=[10, 6])
ax.plot(α_arr, KL_g_arr, label='KL(h, g)')
ax.plot(α_arr, KL_f_arr, label='KL(h, f)')
ax.set_ylabel('KL divergence')
ax.set_xlabel(r'$\alpha$')
ax.legend(loc='upper right')
plt.show()
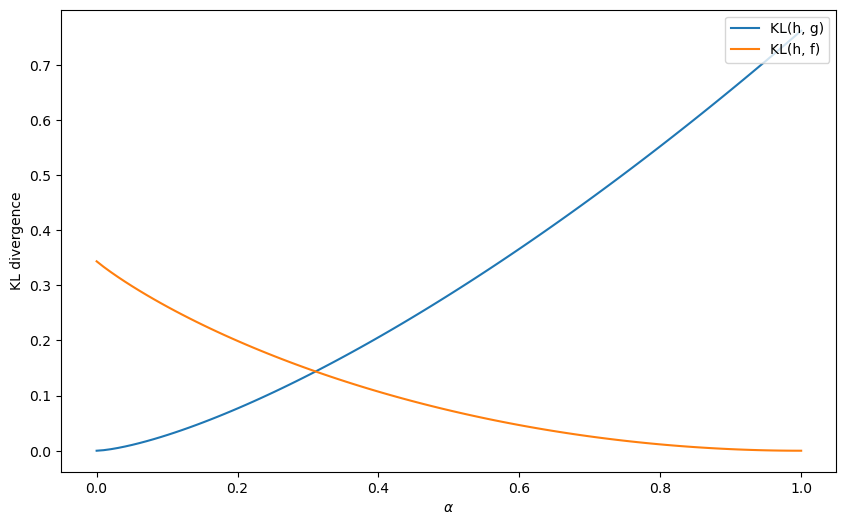
Let’s compute an \(\alpha\) for which the KL divergence between \(h\) and \(g\) is the same as that between \(h\) and \(f\).
# where KL_f = KL_g
discretion = α_arr[np.argmin(np.abs(KL_g_arr-KL_f_arr))]
We can compute and plot the convergence point \(\pi_{\infty}\) for each \(\alpha\) to verify that the convergence is indeed governed by the KL divergence.
The blue circles show the limiting values of \(\pi_t\) that simulations discover for different values of \(\alpha\) recorded on the \(x\) axis.
Thus, the graph below confirms how a minimum KL divergence governs what our type 1 agent eventually learns.
α_arr_x = α_arr[(α_arr<discretion)|(α_arr>discretion)]
π_lim_arr = π_lim_v(α_arr_x)
# plot
fig, ax = plt.subplots(1, figsize=[10, 6])
ax.plot(α_arr, KL_g_arr, label='KL(h, g)')
ax.plot(α_arr, KL_f_arr, label='KL(h, f)')
ax.set_ylabel('KL divergence')
ax.set_xlabel(r'$\alpha$')
# plot KL
ax2 = ax.twinx()
# plot limit point
ax2.scatter(α_arr_x, π_lim_arr,
facecolors='none',
edgecolors='tab:blue',
label=r'$\pi$ lim')
ax2.set_ylabel('π lim')
ax.legend(loc=[0.85, 0.8])
ax2.legend(loc=[0.85, 0.73])
plt.show()
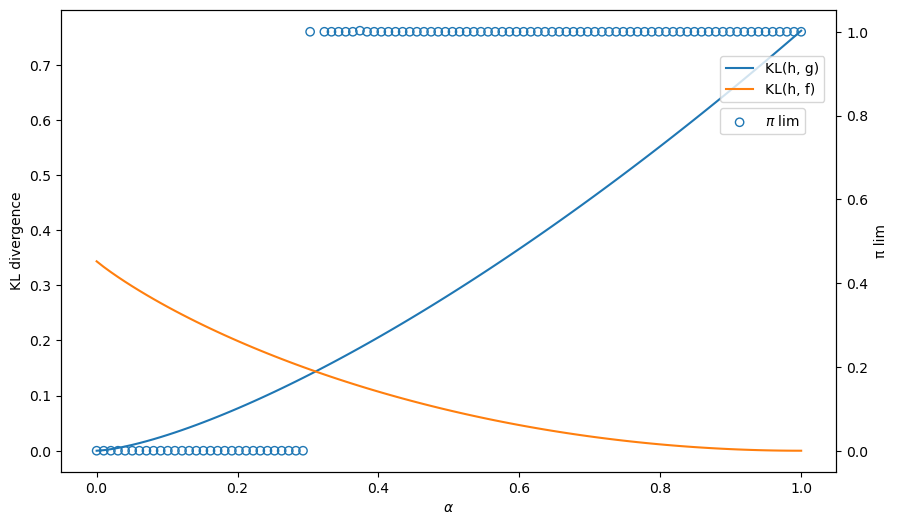
Evidently, our type 1 learner who applies Bayes’ law to his misspecified set of statistical models eventually learns an approximating model that is as close as possible to the true model, as measured by its Kullback-Leibler divergence:
When \(\alpha\) is small, \(KL_g < KL_f\) meaning the divergence of \(g\) from \(h\) is smaller than that of \(f\) and so the limit point of \(\pi_t\) is close to \(0\).
When \(\alpha\) is large, \(KL_f < KL_g\) meaning the divergence of \(f\) from \(h\) is smaller than that of \(g\) and so the limit point of \(\pi_t\) is close to \(1\).
32.6. Type 2 Agent#
We now describe how our type 2 agent formulates his learning problem and what he eventually learns.
Our type 2 agent understands the correct statistical model but does not know \(\alpha\).
We apply Bayes law to deduce an algorithm for learning \(\alpha\) under the assumption that the agent knows that
but does not know \(\alpha\).
We’ll assume that the person starts out with a prior probability \(\pi_0(\alpha)\) on \(\alpha \in (0,1)\) where the prior has one of the forms that we deployed in this quantecon lecture.
We’ll fire up numpyro and apply it to the present situation.
Bayes’ law now takes the form
We’ll use numpyro to approximate this equation.
We’ll create graphs of the posterior \(\pi_t(\alpha)\) as \(t \rightarrow +\infty\) corresponding to ones presented in the quantecon lecture https://python.quantecon.org/bayes_nonconj.html.
We anticipate that a posterior distribution will collapse around the true \(\alpha\) as \(t \rightarrow + \infty\).
Let us try a uniform prior first.
We use the Mixture class in numpyro to construct the likelihood function.
α = 0.8
# simulate data with true α
data = draw_lottery(α, 1000)
sizes = [5, 20, 50, 200, 1000, 25000]
def model(w):
α = numpyro.sample('α', dist.Uniform(low=0.0, high=1.0))
y_samp = numpyro.sample('w',
dist.Mixture(dist.Categorical(jnp.array([α, 1-α])), [dist.Beta(F_a, F_b), dist.Beta(G_a, G_b)]), obs=w)
def MCMC_run(ws):
"Compute posterior using MCMC with observed ws"
kernel = NUTS(model)
mcmc = MCMC(kernel, num_samples=5000, num_warmup=1000, progress_bar=False)
mcmc.run(rng_key=random.PRNGKey(142857), w=jnp.array(ws))
sample = mcmc.get_samples()
return sample['α']
The following code generates the graph below that displays Bayesian posteriors for \(\alpha\) at various history lengths.
fig, ax = plt.subplots(figsize=(10, 6))
for i in range(len(sizes)):
sample = MCMC_run(data[:sizes[i]])
sns.histplot(
data=sample, kde=True, stat='density', alpha=0.2, ax=ax,
color=colors[i], binwidth=0.02, linewidth=0.05, label=f't={sizes[i]}'
)
ax.set_title(r'$\pi_t(\alpha)$ as $t$ increases')
ax.legend()
ax.set_xlabel(r'$\alpha$')
plt.show()
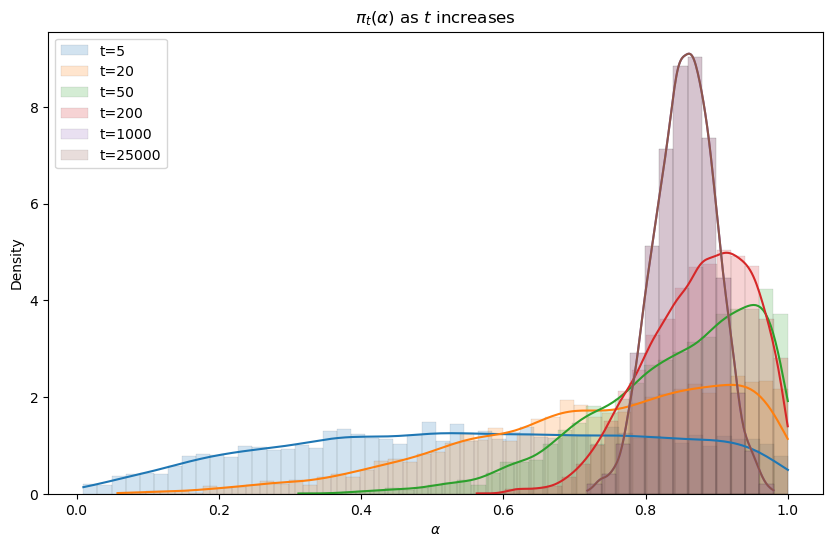
Evidently, the Bayesian posterior narrows in on the true value \(\alpha = .8\) of the mixing parameter as the length of a history of observations grows.
32.7. Concluding Remarks#
Our type 1 person deploys an incorrect statistical model.
He believes that either \(f\) or \(g\) generated the \(w\) process, but just doesn’t know which one.
That is wrong because nature is actually mixing each period with mixing probability \(\alpha\).
Our type 1 agent eventually believes that either \(f\) or \(g\) generated the \(w\) sequence, the outcome being determined by the model, either \(f\) or \(g\), whose KL divergence relative to \(h\) is smaller.
Our type 2 agent has a different statistical model, one that is correctly specified.
He knows the parametric form of the statistical model but not the mixing parameter \(\alpha\).
He knows that he does not know it.
But by using Bayes’ law in conjunction with his statistical model and a history of data, he eventually acquires a more and more accurate inference about \(\alpha\).
This little laboratory exhibits some important general principles that govern outcomes of Bayesian learning of misspecified models.
Thus, the following situation prevails quite generally in empirical work.
A scientist approaches the data with a manifold \(S\) of statistical models \( s (X | \theta)\) , where \(s\) is a probability distribution over a random vector \(X\), \(\theta \in \Theta\) is a vector of parameters, and \(\Theta\) indexes the manifold of models.
The scientist with observations that he interprets as realizations \(x\) of the random vector \(X\) wants to solve an inverse problem of somehow inverting \(s(x | \theta)\) to infer \(\theta\) from \(x\).
But the scientist’s model is misspecified, being only an approximation to an unknown model \(h\) that nature uses to generate \(X\).
If the scientist uses Bayes’ law or a related likelihood-based method to infer \(\theta\), it occurs quite generally that for large sample sizes the inverse problem infers a \(\theta\) that minimizes the KL divergence of the scientist’s model \(s\) relative to nature’s model \(h\).
32.8. Exercises#
Exercise 32.1
In Likelihood Ratio Processes and Bayesian Learning, we studied the consequence of applying likelihood ratio and Bayes’ law to a misspecified statistical model.
In that lecture, we used a model selection algorithm to study the case where the true data generating process is a mixture.
In this lecture, we studied how to correctly “learn” a model generated by a mixing process using a Bayesian approach.
To fix the algorithm we used in Likelihood Ratio Processes and Bayesian Learning, a correct Bayesian approach should directly model the uncertainty about \(x\) and update beliefs about it as new data arrives.
Here is the algorithm:
First we specify a prior distribution for \(x\) given by \(x \sim \text{Beta}(\alpha_0, \beta_0)\) with expectation \(\mathbb{E}[x] = \frac{\alpha_0}{\alpha_0 + \beta_0}\).
The likelihood for a single observation \(w_t\) is \(p(w_t|x) = x f(w_t) + (1-x) g(w_t)\).
For a sequence \(w^t = (w_1, \dots, w_t)\), the likelihood is \(p(w^t|x) = \prod_{i=1}^t p(w_i|x)\).
The posterior distribution is updated using \(p(x|w^t) \propto p(w^t|x) p(x)\).
Recursively, the posterior after \(w_t\) is \(p(x|w^t) \propto p(w_t|x) p(x|w^{t-1})\).
Without a conjugate prior, we can approximate the posterior by discretizing \(x\) into a grid.
Your task is to implement this algorithm in Python.
You can verify your implementation by checking that the posterior mean converges to the true value of \(x\) as \(t\) increases in Likelihood Ratio Processes and Bayesian Learning.
Solution
Here is one solution:
First we define the mixture probability and parameters of prior distributions
x_true = 0.5
T_mix = 200
# Three different priors with means 0.25, 0.5, 0.75
prior_params = [(1, 3), (1, 1), (3, 1)]
prior_means = [a/(a+b) for a, b in prior_params]
w_mix = draw_lottery(x_true, T_mix)
@jit
def learn_x_bayesian(observations, α0, β0, grid_size=2000):
"""
Sequential Bayesian learning of the mixing probability x
using a grid approximation.
"""
w = np.asarray(observations)
T = w.size
x_grid = np.linspace(1e-3, 1 - 1e-3, grid_size)
# Log prior
log_prior = (α0 - 1) * np.log(x_grid) + (β0 - 1) * np.log1p(-x_grid)
μ_path = np.empty(T + 1)
μ_path[0] = α0 / (α0 + β0)
log_post = log_prior.copy()
for t in range(T):
wt = w[t]
# P(w_t | x) = x f(w_t) + (1 - x) g(w_t)
like = x_grid * f(wt) + (1 - x_grid) * g(wt)
log_post += np.log(like)
# normalize
log_post -= log_post.max()
post = np.exp(log_post)
post /= post.sum()
μ_path[t + 1] = x_grid @ post
return μ_path
x_posterior_means = [learn_x_bayesian(w_mix, α0, β0) for α0, β0 in prior_params]
Let’s visualize how the posterior mean of \(x\) evolves over time, starting from three different prior beliefs.
fig, ax = plt.subplots(figsize=(10, 6))
for i, (x_means, mean0) in enumerate(zip(x_posterior_means, prior_means)):
ax.plot(range(T_mix + 1), x_means,
label=fr'Prior mean = ${mean0:.2f}$',
color=colors[i], linewidth=2)
ax.axhline(y=x_true, color='black', linestyle='--',
label=f'True x = {x_true}', linewidth=2)
ax.set_xlabel('$t$')
ax.set_ylabel('Posterior mean of $x$')
ax.legend()
plt.show()
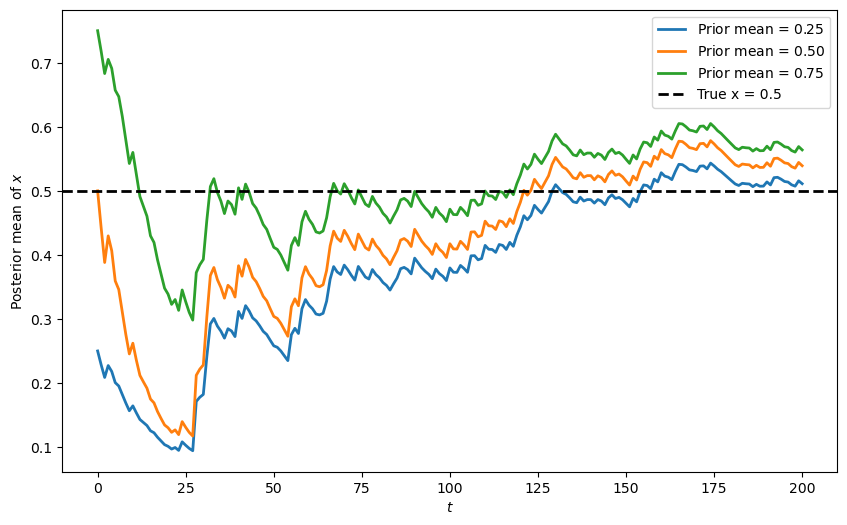
The plot shows that regardless of the initial prior belief, all three posterior means eventually converge towards the true value of \(x=0.5\).
Next, let’s look at multiple simulations with a longer time horizon, all starting from a uniform prior.
set_seed()
n_paths = 20
T_long = 10_000
fig, ax = plt.subplots(figsize=(10, 5))
for j in range(n_paths):
w_path = draw_lottery(x_true, T_long)
x_means = learn_x_bayesian(w_path, 1, 1) # Uniform prior
ax.plot(range(T_long + 1), x_means, alpha=0.5, linewidth=1)
ax.axhline(y=x_true, color='red', linestyle='--',
label=f'True x = {x_true}', linewidth=2)
ax.set_ylabel('Posterior mean of $x$')
ax.set_xlabel('$t$')
ax.legend()
plt.tight_layout()
plt.show()
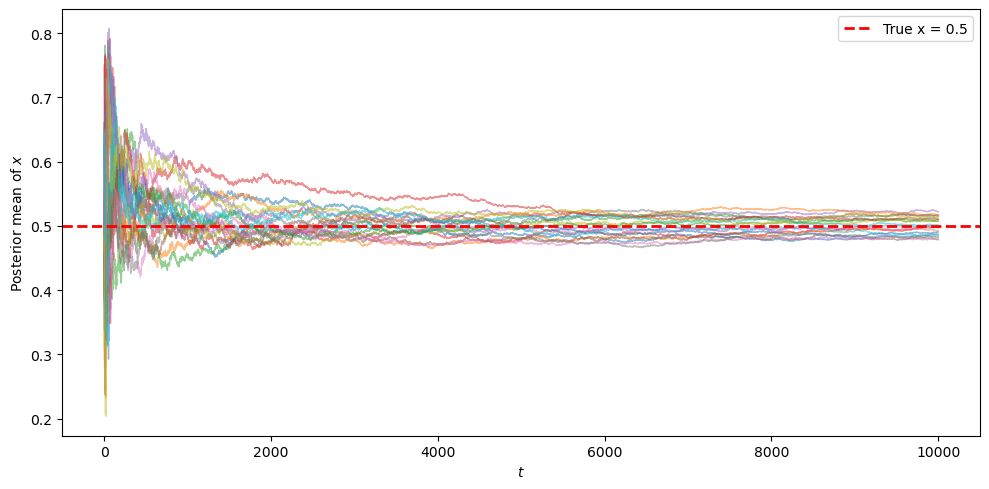
We can see that the posterior mean of \(x\) converges to the true value \(x=0.5\).