11. Two Meanings of Probability#
11.1. Overview#
This lecture illustrates two distinct interpretations of a probability distribution
A frequentist interpretation as relative frequencies anticipated to occur in a large IID sample
A Bayesian interpretation as a personal opinion (about a parameter or list of parameters) after seeing a collection of observations
We recommend watching the following two videos before proceeding:
After you are familiar with the material in these videos, this lecture uses the Socratic method to help consolidate your understanding of these two meanings of probability.
Along the way we construct a Bayesian coverage interval and contrast the question it answers with the frequentist relative-frequency reasoning that opens the lecture.
We do this by inviting you to write some Python code.
It would be especially useful if you tried doing this after each question that we pose for you, before proceeding to read the rest of the lecture.
We provide our own answers as the lecture unfolds, but you’ll learn more if you try writing your own code before reading and running ours.
11.1.1. Code for answering questions#
To answer our coding questions, we’ll start with some imports
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import binom
import scipy.stats as st
Empowered with these Python tools, we’ll now explore the two meanings described above.
11.2. Frequentist Interpretation#
Consider the following classic example.
The random variable \(X \) takes on possible values \(k = 0, 1, 2, \ldots, n\) with probabilities
where the fixed parameter \(\theta \in (0,1)\).
This is called the binomial distribution.
Here
\(\theta\) is the probability that one toss of a coin will be a head, an outcome that we encode as \(Y = 1\).
\(1 -\theta\) is the probability that one toss of the coin will be a tail, an outcome that we denote \(Y = 0\).
\(X\) is the total number of heads that came up after flipping the coin \(n\) times.
Consider the following experiment:
Take \(I\) independent sequences of \(n\) independent flips of the coin
Notice the repeated use of the adjective independent:
we use it once to describe that we are drawing \(n\) independent times from a Bernoulli distribution with parameter \(\theta\) to arrive at one draw from a Binomial distribution with parameters \(\theta,n\).
we use it again to describe that we are then drawing \(I\) sequences of \(n\) coin draws.
Let \(y_h^i \in \{0, 1\}\) be the realized value of \(Y\) on the \(h\)th flip during the \(i\)th sequence of flips.
Let \(\sum_{h=1}^n y_h^i\) denote the total number of times heads come up during the \(i\)th sequence of \(n\) independent coin flips.
Let \(f_k\) record the fraction of samples of length \(n\) for which \(\sum_{h=1}^n y_h^i = k\):
The probability \(p(k \mid \theta)\) answers the following question:
As \(I\) becomes large, in what fraction of \(I\) independent draws of \(n\) coin flips should we anticipate \(k\) heads to occur?
As usual, a law of large numbers justifies this answer.
Exercise 11.1
Write Python code to compute \(f_k^I\)
Use your code to compute \(f_k^I, k = 0, \ldots , n\) and compare them to \(p(k \mid \theta)\) for various values of \(\theta, n\) and \(I\)
With the Law of Large Numbers in mind, use your code to describe the relationship between \(f_k^I\) and \(p(k \mid \theta)\) as \(I\) grows
Solution
Here is one solution.
We simulate the coin flips with one function and assemble the comparison table with another.
def simulate_head_counts(θ, n, I, seed=1234):
"Simulate I sequences of n coin flips; return the heads count of each sequence."
rng = np.random.default_rng(seed)
Y = (rng.random((I, n)) <= θ).astype(int)
return Y.sum(axis=1)
def compare_frequencies(θ, n, I, seed=1234):
"Tabulate theoretical binomial probabilities against simulated frequencies."
head_counts = simulate_head_counts(θ, n, I, seed)
rows = [
(k, binom.pmf(k, n, θ), np.mean(head_counts == k))
for k in range(n + 1)
]
return pd.DataFrame(
rows, columns=['k', 'Theoretical', 'Frequentist']
).set_index('k')
θ, n, k, I = 0.7, 20, 10, 1_000_000
compare_frequencies(θ, n, I)
| Theoretical | Frequentist | |
|---|---|---|
| k | ||
| 0 | 3.486784e-11 | 0.000000 |
| 1 | 1.627166e-09 | 0.000000 |
| 2 | 3.606885e-08 | 0.000000 |
| 3 | 5.049639e-07 | 0.000000 |
| 4 | 5.007558e-06 | 0.000002 |
| 5 | 3.738977e-05 | 0.000047 |
| 6 | 2.181070e-04 | 0.000247 |
| 7 | 1.017833e-03 | 0.001029 |
| 8 | 3.859282e-03 | 0.003721 |
| 9 | 1.200665e-02 | 0.011986 |
| 10 | 3.081708e-02 | 0.030698 |
| 11 | 6.536957e-02 | 0.065110 |
| 12 | 1.143967e-01 | 0.114892 |
| 13 | 1.642620e-01 | 0.164639 |
| 14 | 1.916390e-01 | 0.191724 |
| 15 | 1.788631e-01 | 0.178623 |
| 16 | 1.304210e-01 | 0.129870 |
| 17 | 7.160367e-02 | 0.072004 |
| 18 | 2.784587e-02 | 0.027818 |
| 19 | 6.839337e-03 | 0.006836 |
| 20 | 7.979227e-04 | 0.000754 |
From the table above, can you see the law of large numbers at work?
Let’s do some more calculations.
11.2.1. Comparison with different \(\theta\)#
Now we fix
We’ll vary \(\theta\) from \(0.01\) to \(0.99\) and plot outcomes against \(\theta\).
θ_low, θ_high, n_thetas = 0.01, 0.99, 50
thetas = np.linspace(θ_low, θ_high, n_thetas)
P = []
f_kI = []
for i in range(n_thetas):
P.append(binom.pmf(k, n, thetas[i]))
head_counts = simulate_head_counts(thetas[i], n, I, seed=i)
f_kI.append(np.mean(head_counts == k))
fig, ax = plt.subplots(figsize=(8, 6))
ax.grid()
ax.plot(thetas, P, '-.', label='theoretical')
ax.plot(thetas, f_kI, '--', label='fraction')
ax.set_title(r'comparison with different $\theta$',
fontsize=16)
ax.set_xlabel(r'$\theta$', fontsize=15)
ax.set_ylabel('fraction', fontsize=15)
ax.tick_params(labelsize=13)
ax.legend()
plt.show()
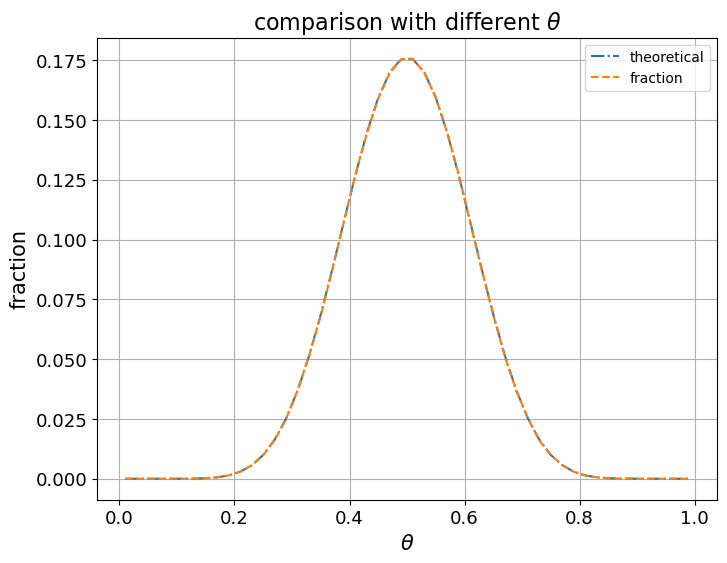
11.2.2. Comparison with different \(n\)#
Now we fix \(\theta=0.7, k=10, I=1,000,000\) and vary \(n\) from \(1\) to \(100\).
Then we’ll plot outcomes.
n_low, n_high, n_ns = 1, 100, 50
ns = np.linspace(n_low, n_high, n_ns, dtype='int')
P = []
f_kI = []
for i in range(n_ns):
P.append(binom.pmf(k, ns[i], θ))
head_counts = simulate_head_counts(θ, ns[i], I, seed=i)
f_kI.append(np.mean(head_counts == k))
fig, ax = plt.subplots(figsize=(8, 6))
ax.grid()
ax.plot(ns, P, '-.', label='theoretical')
ax.plot(ns, f_kI, '--', label='fraction')
ax.set_title(r'comparison with different $n$',
fontsize=16)
ax.set_xlabel(r'$n$', fontsize=15)
ax.set_ylabel('fraction', fontsize=15)
ax.tick_params(labelsize=13)
ax.legend()
plt.show()
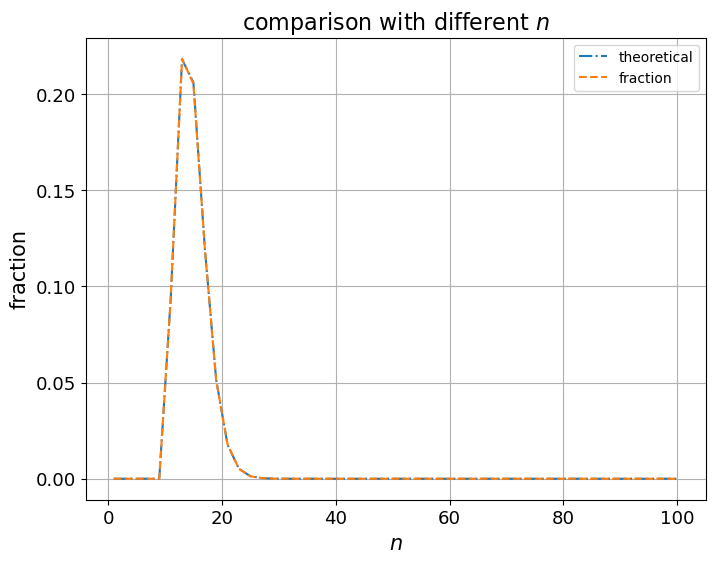
Because \(k=10\) is held fixed, \(p(k \mid \theta)\) is zero whenever \(n < 10\) — we cannot obtain \(10\) heads in fewer than \(10\) flips — and it is largest near \(n \approx 14\), where the expected number of heads \(n\theta\) is closest to \(k\). The simulated fraction tracks this shape.
11.2.3. Comparison with different \(I\)#
Now we fix \(\theta=0.7, n=20, k=10\) and vary \(\log(I)\) from \(2\) to \(6\).
I_log_low, I_log_high, n_Is = 2, 6, 200
log_Is = np.linspace(I_log_low, I_log_high, n_Is)
Is = np.power(10, log_Is).astype(int)
P = []
f_kI = []
for i in range(n_Is):
P.append(binom.pmf(k, n, θ))
head_counts = simulate_head_counts(θ, n, Is[i], seed=i)
f_kI.append(np.mean(head_counts == k))
fig, ax = plt.subplots(figsize=(8, 6))
ax.grid()
ax.plot(Is, P, '-.', label='theoretical')
ax.plot(Is, f_kI, '--', label='fraction')
ax.set_title(r'comparison with different $I$',
fontsize=16)
ax.set_xlabel(r'$I$', fontsize=15)
ax.set_ylabel('fraction', fontsize=15)
ax.tick_params(labelsize=13)
ax.legend()
plt.show()
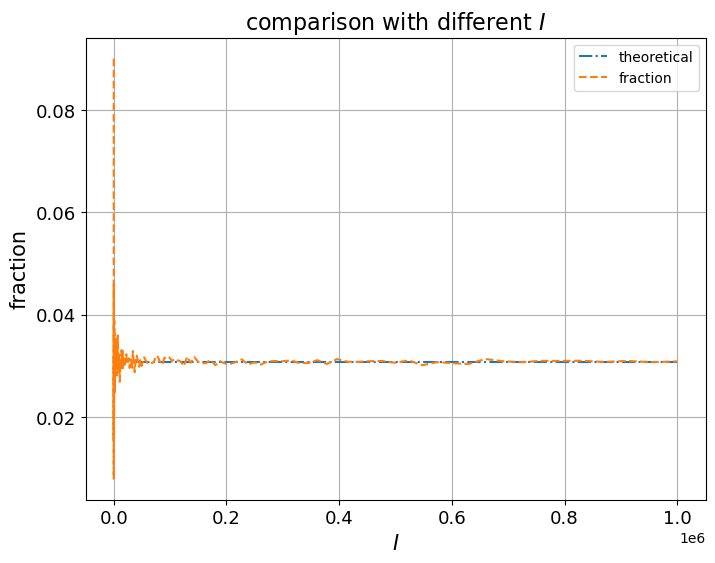
From the above graphs, we can see that \(I\), the number of independent sequences, plays an important role.
When \(I\) becomes larger, the difference between theoretical probability and frequentist estimate becomes smaller.
Also, as long as \(I\) is large enough, changing \(\theta\) or \(n\) does not substantially change the accuracy of the observed fraction as an approximation of \(p(k \mid \theta)\).
The Law of Large Numbers is at work here.
For each independent sequence \(i\), define the indicator \(\rho_{k,i} = \mathbb{1}\{X_i = k\}\) — that is, \(\rho_{k,i}\) equals 1 if the \(i\)-th sequence produces exactly \(k\) heads and 0 otherwise.
The \(\rho_{k,i}\) are IID across \(i\), each with mean \(p(k \mid \theta)\) and variance
So, by the LLN, the average of \(\rho_{k,i}\) converges to:
as \(I\) goes to infinity.
11.3. Bayesian Interpretation#
The likelihood remains binomial, but now we treat \(\theta\) as a random variable rather than a fixed parameter.
So \(\theta\) is described by a probability distribution.
But now this probability distribution means something different than a relative frequency that we can anticipate to occur in a large IID sample.
Instead, the probability distribution of \(\theta\) is now a summary of our views about likely values of \(\theta\) either
before we have seen any data at all, or
before we have seen more data, after we have seen some data
11.3.1. The beta prior and its posterior#
Thus, suppose that, before seeing any data, you have a personal prior probability distribution with density
where \(B(\alpha, \beta)\) is a beta function , so that \(p(\theta)\) is the density of a beta distribution with parameters \(\alpha, \beta\).
We can update this prior after observing data using Bayes’ Law (see Probability with Matrices for an introduction).
For a sample of \(n\) coin flips that yields \(k\) heads, the likelihood function is the binomial PMF \(p(k \mid \theta)\) introduced above.
Applying Bayes’ Law with our beta prior, the posterior density is
Because the beta prior is conjugate to the binomial likelihood, this integral evaluates to (the kernel of) another beta density, so that
The first exercise below asks you to derive this closed form.
Exercise 11.2
a) Write down the likelihood function for a single coin flip with outcome \(Y \in \{0, 1\}\).
b) Write down the posterior distribution for \(\theta\) after observing that single flip.
c) Derive the closed-form posterior (11.1) for a sample of \(n\) flips that yields \(k\) heads.
Solution
a) The likelihood function for a single coin flip with outcome \(Y \in \{0, 1\}\) is
b) By Bayes’ Law, the posterior density for \(\theta\) after observing a single flip \(Y\) is
Substituting the likelihood from (a) and the beta prior density, this becomes
Collecting powers of \(\theta\) and \((1-\theta)\), we recognize the kernel of a beta density:
which means that
c) The same calculation, with the binomial likelihood in place of the Bernoulli likelihood, generalizes the result to a sample of \(n\) flips that yields \(k\) heads.
The beta prior contributes the factor \(\theta^{\alpha-1}(1-\theta)^{\beta-1}\), and the binomial likelihood contributes \(\theta^{k}(1-\theta)^{n-k}\), so the posterior is proportional to
which is the kernel of a beta density. Hence
as stated in (11.1).
11.3.2. Exploring the posterior numerically#
The next exercise puts this posterior to work.
Exercise 11.3
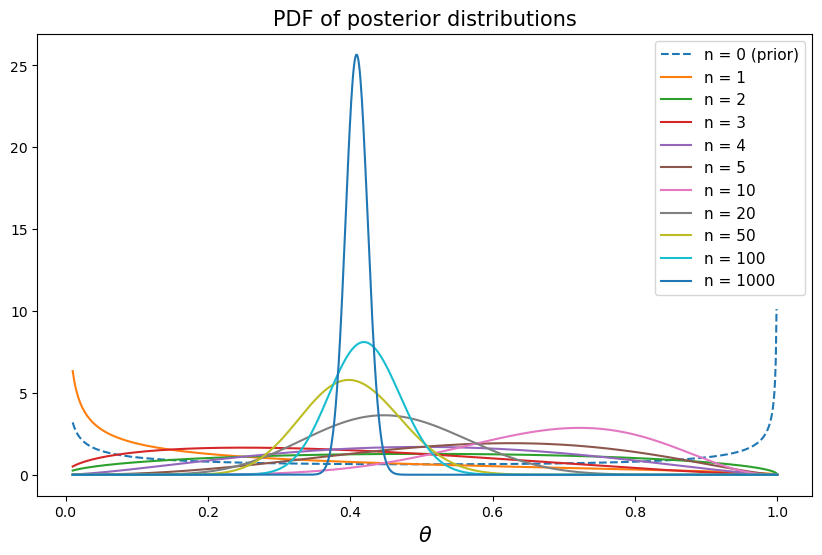
a) Now pretend that the true value of \(\theta = 0.4\) and that someone who doesn’t know this has a beta prior distribution with parameters \(\beta = \alpha = 0.5\). Write Python code to simulate this person’s personal posterior distribution for \(\theta\) for a single sequence of \(n\) draws.
b) Plot the posterior distribution for \(\theta\) as a function of \(\theta\) as \(n\) grows as \(1, 2, \ldots\).
c) For various \(n\)’s, describe and compute a Bayesian coverage interval for the interval \([0.45, 0.55]\).
d) Tell what question a Bayesian coverage interval answers.
e) Compute the posterior probability that \(\theta \in [0.45, 0.55]\) for various values of sample size \(n\).
f) Use your Python code to study what happens to the posterior distribution as \(n \rightarrow + \infty\), again assuming that the true value of \(\theta = 0.4\), though it is unknown to the person doing the updating via Bayes’ Law.
Solution
a)
We use one function to simulate a sequence of coin flips and another to form the
Beta posterior from the first n_obs of those flips.
def simulate_flips(θ=0.4, n=1_000_000, seed=1234):
"Simulate n coin flips, each landing heads (1) with probability θ."
rng = np.random.default_rng(seed)
return (rng.random(n) < θ).astype(int)
def form_posterior(draws, n_obs, α=0.5, β=0.5):
"Beta posterior for θ from the first n_obs flips, given a Beta(α, β) prior."
heads = draws[:n_obs].sum()
return st.beta(α + heads, β + n_obs - heads)
b)
draws = simulate_flips()
n_obs_list = [1, 2, 3, 4, 5, 10, 20, 50,
100, 1000,
5000, 10_000, 50_000, 100_000,
200_000, 300_000]
posterior_list = [form_posterior(draws, n_obs) for n_obs in n_obs_list]
θ_values = np.linspace(0.01, 1, 1000)
fig, ax = plt.subplots(figsize=(10, 6))
prior = st.beta(0.5, 0.5)
ax.plot(θ_values, prior.pdf(θ_values),
label='n = 0 (prior)', linestyle='--')
for i, n_obs in enumerate(n_obs_list[:10]):
posterior = posterior_list[i]
ax.plot(θ_values, posterior.pdf(θ_values),
label=f'n = {n_obs}')
ax.set_title('PDF of posterior distributions',
fontsize=15)
ax.set_xlabel(r"$\theta$", fontsize=15)
ax.legend(fontsize=11)
plt.show()
c)
lower_bound = [post.ppf(0.05) for post in posterior_list[:10]]
upper_bound = [post.ppf(0.95) for post in posterior_list[:10]]
interval_df = pd.DataFrame()
interval_df['upper'] = upper_bound
interval_df['lower'] = lower_bound
interval_df.index = n_obs_list[:10]
interval_df = interval_df.T
interval_df
| 1 | 2 | 3 | 4 | 5 | 10 | 20 | 50 | 100 | 1000 | |
|---|---|---|---|---|---|---|---|---|---|---|
| upper | 0.771480 | 0.902692 | 0.764466 | 0.83472 | 0.872224 | 0.882671 | 0.629953 | 0.516104 | 0.502138 | 0.434744 |
| lower | 0.001543 | 0.097308 | 0.062413 | 0.16528 | 0.260634 | 0.441873 | 0.280091 | 0.292234 | 0.341239 | 0.383644 |
As \(n\) increases, we can see that Bayesian coverage intervals narrow and move toward \(0.4\).
d) The Bayesian coverage interval tells the range of \(\theta\) that corresponds to the [\(q_1\), \(q_2\)] quantiles of the cumulative distribution function (CDF) of the posterior distribution.
To construct the coverage interval we first compute a posterior distribution of the unknown parameter \(\theta\).
If the CDF is \(F(\theta)\), then the Bayesian coverage interval \([a,b]\) for the interval \([q_1,q_2]\) is described by
e)
left_value, right_value = 0.45, 0.55
posterior_prob_list = [
post.cdf(right_value) - post.cdf(left_value)
for post in posterior_list
]
fig, ax = plt.subplots(figsize=(8, 5))
ax.plot(posterior_prob_list)
ax.set_title(
r'posterior probability that $\theta$'
f' ranges from {left_value:.2f}'
f' to {right_value:.2f}',
fontsize=13)
ax.set_xticks(np.arange(0, len(posterior_prob_list), 3))
ax.set_xticklabels(n_obs_list[::3])
ax.set_xlabel('number of observations', fontsize=11)
plt.show()
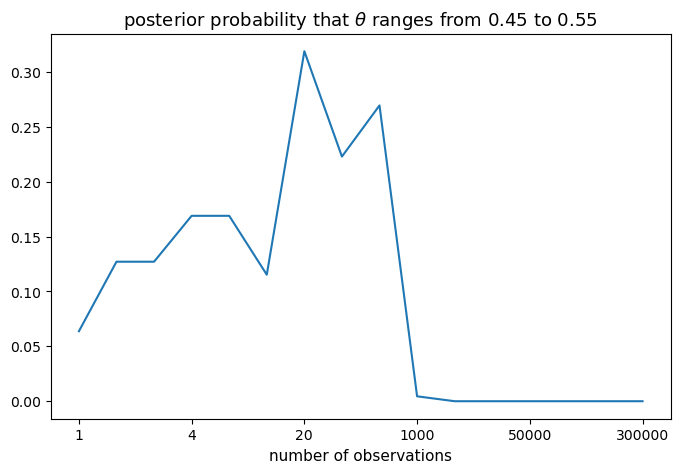
Notice that in the graph above the posterior probability that \(\theta \in [0.45, 0.55]\) exhibits a hump shape as \(n\) increases.
Two opposing forces are at work.
The first force is that the individual adjusts his belief as he observes new outcomes, so his posterior probability distribution becomes more and more realistic, which explains the rise of the posterior probability.
However, \([0.45, 0.55]\) actually excludes the true \(\theta = 0.4\) that generates the data.
As a result, the posterior probability drops as larger and larger samples refine his posterior probability distribution of \(\theta\).
The descent seems precipitous only because of the scale of the graph that has the number of observations increasing disproportionately.
When the number of observations becomes large enough, our Bayesian becomes so confident about \(\theta\) that he considers \(\theta \in [0.45, 0.55]\) very unlikely.
That is why we see a nearly horizontal line when the number of observations exceeds 1000.
f) Using the functions we wrote above, we can see the evolution of posterior distributions as \(n\) approaches infinity.
fig, ax = plt.subplots(figsize=(10, 6))
for i, n_obs in enumerate(n_obs_list[10:]):
posterior = posterior_list[i + 10]
ax.plot(θ_values, posterior.pdf(θ_values),
label=f'n = {n_obs:,}')
ax.set_title('PDF of posterior distributions', fontsize=15)
ax.set_xlabel(r"$\theta$", fontsize=15)
ax.set_xlim(0.3, 0.5)
ax.legend(fontsize=11)
plt.show()
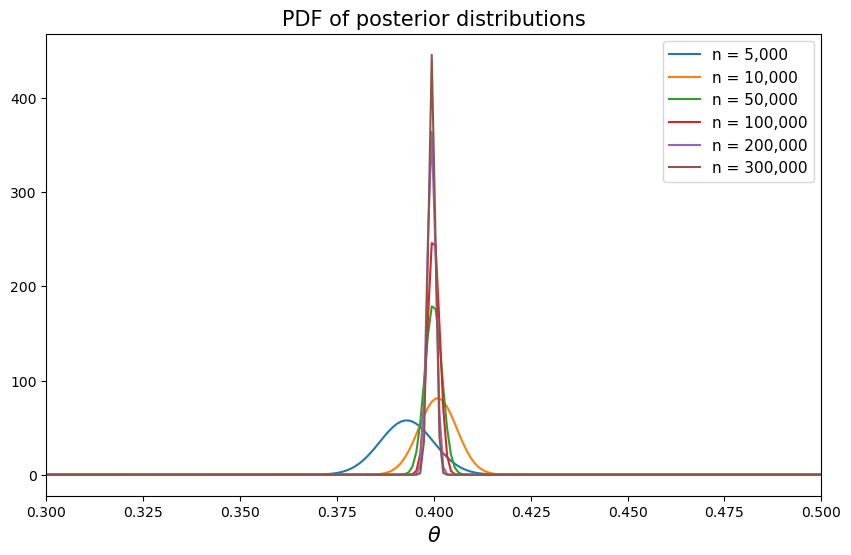
As \(n\) increases, we can see that the probability density functions concentrate on \(0.4\), the true value of \(\theta\).
The next section explains why this concentration occurs and how fast it happens.
11.3.3. Why the posterior concentrates#
In the solution to Exercise 11.3 we watched the posterior distribution concentrate ever more tightly around the true value \(\theta = 0.4\) as the sample grew. Why does this happen?
The answer is encoded in the posterior we derived.
Recall that after observing \(k\) heads in \(n\) flips, the posterior is \(\textrm{Beta}(\alpha + k, \, \beta + n - k)\).
A beta distribution with parameters \(a\) and \(b\) has
mean \(\dfrac{a}{a + b}\),
variance \(\dfrac{a\, b}{(a + b)^2\, (a + b + 1)}\).
Substituting the posterior parameters \(a = \alpha + k\) and \(b = \beta + n - k\), so that \(a + b = \alpha + \beta + n\), gives
As \(n\) grows, the fixed prior counts \(\alpha\) and \(\beta\) become negligible beside the data.
Since the data are generated with \(\theta = 0.4\), the Law of Large Numbers gives \(k/n \to 0.4\) (see Exercise 11.1), so the posterior mean
In the variance, the numerator grows like \(n^2\) while the denominator grows like \(n^3\), so
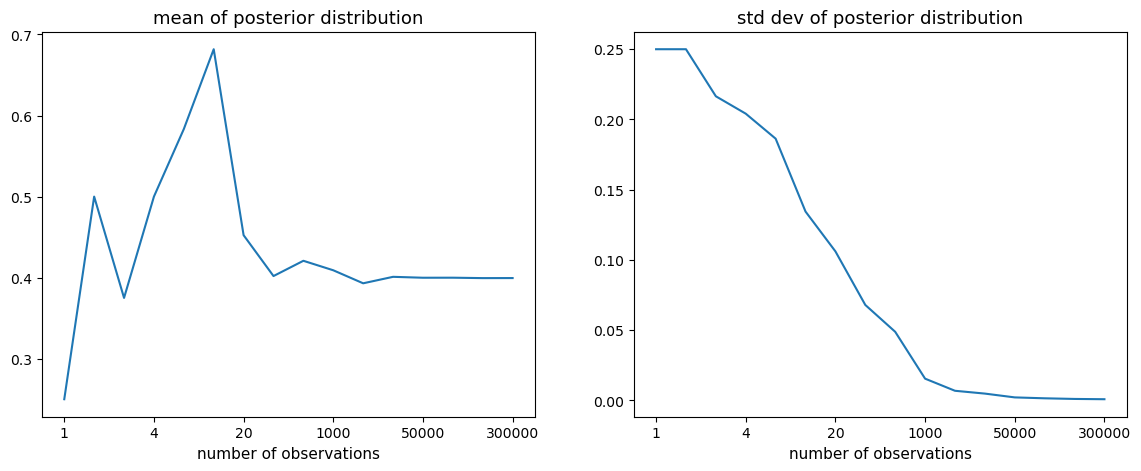
The posterior mean therefore homes in on the truth while its spread vanishes at rate \(1/n\).
The next figure confirms both claims: the posterior mean settles on \(0.4\) and the standard deviation decays toward zero.
mean_list = [post.mean() for post in posterior_list]
std_list = [post.std() for post in posterior_list]
fig, ax = plt.subplots(1, 2, figsize=(14, 5))
ax[0].plot(mean_list)
ax[0].set_title('mean of posterior distribution',
fontsize=13)
ax[0].set_xticks(np.arange(0, len(mean_list), 3))
ax[0].set_xticklabels(n_obs_list[::3])
ax[0].set_xlabel('number of observations', fontsize=11)
ax[1].plot(std_list)
ax[1].set_title('std dev of posterior distribution',
fontsize=13)
ax[1].set_xticks(np.arange(0, len(std_list), 3))
ax[1].set_xticklabels(n_obs_list[::3])
ax[1].set_xlabel('number of observations', fontsize=11)
plt.show()
We can also display the Bayesian coverage intervals directly.
The box-and-whisker plot below summarizes each posterior by its median (central line), interquartile range (box), and \(5\)th–\(95\)th percentile range (whiskers), with the true value \(\theta = 0.4\) marked.
quantiles = [0.05, 0.25, 0.5, 0.75, 0.95]
box_stats = []
for post in posterior_list:
lo, q1, med, q3, hi = post.ppf(quantiles)
box_stats.append({'med': med, 'q1': q1, 'q3': q3,
'whislo': lo, 'whishi': hi, 'fliers': []})
fig, ax = plt.subplots(figsize=(10, 6))
ax.bxp(box_stats, positions=np.arange(len(box_stats)), showfliers=False)
ax.axhline(0.4, color='C1', linestyle='--', label=r'true $\theta = 0.4$')
ax.set_xticks(np.arange(len(box_stats)))
ax.set_xticklabels(n_obs_list, rotation=45)
ax.set_xlabel('number of observations', fontsize=12)
ax.set_ylabel(r'$\theta$', fontsize=12)
ax.set_title('posterior coverage intervals as $n$ grows', fontsize=15)
ax.legend(fontsize=11)
plt.show()
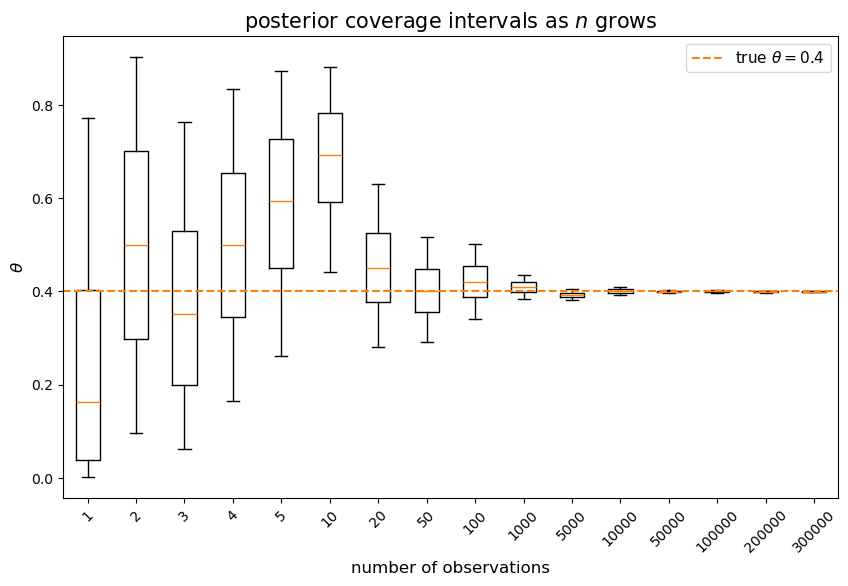
After observing a large number of outcomes, the posterior distribution collapses around \(0.4\).
Thus, the Bayesian statistician comes to believe that \(\theta\) is near \(0.4\).
As shown in the figure above, as the number of observations grows, the Bayesian coverage intervals (BCIs) become narrower and narrower around \(0.4\).
However, if you take a closer look, you will find that the centers of the BCIs are not exactly \(0.4\), due to the persistent influence of the prior distribution and the randomness of the simulation path.
11.4. Comparing the two interpretations#
We can now place the two meanings of probability side by side.
In the frequentist calculations, \(\theta\) was a fixed number and a probability was a relative frequency: \(p(k \mid \theta)\) is the fraction of a large number of independent length-\(n\) sequences in which exactly \(k\) heads occur, and we confirmed by simulation that \(f_k^I \to p(k \mid \theta)\) as \(I \to \infty\).
In the Bayesian calculations, \(\theta\) was itself a random variable describing our beliefs, and a probability was a degree of belief. The Bayesian coverage interval summarizes the posterior \(p(\theta \mid k)\): it reports the range of \(\theta\) lying between two posterior quantiles, and so answers the question “given the data I have seen and my prior, where do I now believe \(\theta\) lies?”
These are genuinely different questions, even though both rest on the same binomial likelihood. The frequentist statement describes the data-generating mechanism for a fixed \(\theta\); the Bayesian statement describes our uncertainty about \(\theta\) given the particular data we happened to observe.
11.5. Role of a Conjugate Prior#
We have made assumptions that link functional forms of our likelihood function and our prior in a way that has eased our calculations considerably.
In particular, our assumptions that the likelihood function is binomial and that the prior distribution is a beta distribution have the consequence that the posterior distribution implied by Bayes’ Law is also a beta distribution.
So posterior and prior are both beta distributions, albeit ones with different parameters.
When a likelihood function and prior fit together like hand and glove in this way, we can say that the prior and posterior are conjugate distributions.
In this situation, we also sometimes say that we have conjugate prior for the likelihood function \(p(k \mid \theta)\).
Typically, the functional form of the likelihood function determines the functional form of a conjugate prior.
A natural question to ask is why should a person’s personal prior about a parameter \(\theta\) be restricted to be described by a conjugate prior?
Why not some other functional form that more sincerely describes the person’s beliefs?
To be argumentative, one could ask, why should the form of the likelihood function have anything to say about my personal beliefs about \(\theta\)?
A dignified response to that question is, well, it shouldn’t, but if you want to compute a posterior easily you’ll just be happier if your prior is conjugate to your likelihood.
Otherwise, your posterior won’t have a convenient analytical form and you’ll be in the situation of wanting to apply the Markov chain Monte Carlo techniques deployed in Non-Conjugate Priors.
We also apply these powerful methods to approximating Bayesian posteriors for non-conjugate priors in Posterior Distributions for AR(1) Parameters and Forecasting an AR(1) Process.