56. Job Search VII: On-the-Job Search#
56.1. Overview#
In this section, we solve a simple on-the-job search model
based on [Ljungqvist and Sargent, 2018], exercise 6.18, and [Jovanovic, 1979]
Let’s start with some imports:
import matplotlib.pyplot as plt
import numpy as np
import scipy.stats as stats
from numba import jit, prange
56.1.1. Model Features#
job-specific human capital accumulation combined with on-the-job search
infinite-horizon dynamic programming with one state variable and two controls
56.2. Model#
Let \(x_t\) denote the time-\(t\) job-specific human capital of a worker employed at a given firm and let \(w_t\) denote current wages.
Let \(w_t = x_t(1 - s_t - \phi_t)\), where
\(\phi_t\) is investment in job-specific human capital for the current role and
\(s_t\) is search effort, devoted to obtaining new offers from other firms.
For as long as the worker remains in the current job, evolution of \(\{x_t\}\) is given by \(x_{t+1} = g(x_t, \phi_t)\).
When search effort at \(t\) is \(s_t\), the worker receives a new job offer with probability \(\pi(s_t) \in [0, 1]\).
The value of the offer, measured in job-specific human capital, is \(u_{t+1}\), where \(\{u_t\}\) is IID with common distribution \(f\).
The worker can reject the current offer and continue with existing job.
Hence \(x_{t+1} = u_{t+1}\) if he/she accepts and \(x_{t+1} = g(x_t, \phi_t)\) otherwise.
Let \(b_{t+1} \in \{0,1\}\) be a binary random variable, where \(b_{t+1} = 1\) indicates that the worker receives an offer at the end of time \(t\).
We can write
Agent’s objective: maximize expected discounted sum of wages via controls \(\{s_t\}\) and \(\{\phi_t\}\).
Taking the expectation of \(v(x_{t+1})\) and using (56.1), the Bellman equation for this problem can be written as
Here nonnegativity of \(s\) and \(\phi\) is understood, while \(a \vee b := \max\{a, b\}\).
56.2.1. Parameterization#
In the implementation below, we will focus on the parameterization
with default parameter values
\(A = 1.4\)
\(\alpha = 0.6\)
\(\beta = 0.96\)
The \(\text{Beta}(2,2)\) distribution is supported on \((0,1)\) - it has a unimodal, symmetric density peaked at 0.5.
56.2.2. Back-of-the-Envelope Calculations#
Before we solve the model, let’s make some quick calculations that provide intuition on what the solution should look like.
To begin, observe that the worker has two instruments to build capital and hence wages:
invest in capital specific to the current job via \(\phi\)
search for a new job with better job-specific capital match via \(s\)
Since wages are \(x (1 - s - \phi)\), marginal cost of investment via either \(\phi\) or \(s\) is identical.
Our risk-neutral worker should focus on whatever instrument has the highest expected return.
The relative expected return will depend on \(x\).
For example, suppose first that \(x = 0.05\)
If \(s=1\) and \(\phi = 0\), then since \(g(x,\phi) = 0\), taking expectations of (56.1) gives expected next period capital equal to \(\pi(s) \mathbb{E} u = \mathbb{E} u = 0.5\).
If \(s=0\) and \(\phi=1\), then next period capital is \(g(x, \phi) = g(0.05, 1) \approx 0.23\).
Both rates of return are good, but the return from search is better.
Next, suppose that \(x = 0.4\)
If \(s=1\) and \(\phi = 0\), then expected next period capital is again \(0.5\)
If \(s=0\) and \(\phi = 1\), then \(g(x, \phi) = g(0.4, 1) \approx 0.8\)
Return from investment via \(\phi\) dominates expected return from search.
Combining these observations gives us two informal predictions:
At any given state \(x\), the two controls \(\phi\) and \(s\) will function primarily as substitutes — worker will focus on whichever instrument has the higher expected return.
For sufficiently small \(x\), search will be preferable to investment in job-specific human capital. For larger \(x\), the reverse will be true.
Now let’s turn to implementation, and see if we can match our predictions.
56.3. Implementation#
We will set up a class JVWorker that holds the parameters of the model described above
class JVWorker:
r"""
A Jovanovic-type model of employment with on-the-job search.
"""
def __init__(self,
A=1.4,
α=0.6,
β=0.96, # Discount factor
π=np.sqrt, # Search effort function
a=2, # Parameter of f
b=2, # Parameter of f
grid_size=50,
mc_size=100,
ɛ=1e-4):
self.A, self.α, self.β, self.π = A, α, β, π
self.mc_size, self.ɛ = mc_size, ɛ
self.g = jit(lambda x, ϕ: A * (x * ϕ)**α) # Transition function
self.f_rvs = np.random.beta(a, b, mc_size)
# Max of grid is the max of a large quantile value for f and the
# fixed point y = g(y, 1)
ɛ = 1e-4
grid_max = max(A**(1 / (1 - α)), stats.beta(a, b).ppf(1 - ɛ))
# Human capital
self.x_grid = np.linspace(ɛ, grid_max, grid_size)
The function operator_factory takes an instance of this class and returns a
jitted version of the Bellman operator T, i.e.
where
When we represent \(v\), it will be with a NumPy array v giving values on grid x_grid.
But to evaluate the right-hand side of (56.3), we need a function, so
we replace the arrays v and x_grid with a function v_func that gives linear
interpolation of v on x_grid.
Inside the for loop, for each x in the grid over the state space, we
set up the function \(w(z) = w(s, \phi)\) defined in (56.3).
The function is maximized over all feasible \((s, \phi)\) pairs.
Another function, get_greedy returns the optimal choice of \(s\) and \(\phi\)
at each \(x\), given a value function.
def operator_factory(jv, parallel_flag=True):
"""
Returns a jitted version of the Bellman operator T
jv is an instance of JVWorker
"""
π, β = jv.π, jv.β
x_grid, ɛ, mc_size = jv.x_grid, jv.ɛ, jv.mc_size
f_rvs, g = jv.f_rvs, jv.g
@jit
def state_action_values(z, x, v):
s, ϕ = z
v_func = lambda x: np.interp(x, x_grid, v)
integral = 0
for m in range(mc_size):
u = f_rvs[m]
integral += v_func(max(g(x, ϕ), u))
integral = integral / mc_size
q = π(s) * integral + (1 - π(s)) * v_func(g(x, ϕ))
return x * (1 - ϕ - s) + β * q
@jit(parallel=parallel_flag)
def T(v):
"""
The Bellman operator
"""
v_new = np.empty_like(v)
for i in prange(len(x_grid)):
x = x_grid[i]
# Search on a grid
search_grid = np.linspace(ɛ, 1, 15)
max_val = -1
for s in search_grid:
for ϕ in search_grid:
current_val = state_action_values((s, ϕ), x, v) if s + ϕ <= 1 else -1
if current_val > max_val:
max_val = current_val
v_new[i] = max_val
return v_new
@jit
def get_greedy(v):
"""
Computes the v-greedy policy of a given function v
"""
s_policy, ϕ_policy = np.empty_like(v), np.empty_like(v)
for i in range(len(x_grid)):
x = x_grid[i]
# Search on a grid
search_grid = np.linspace(ɛ, 1, 15)
max_val = -1
for s in search_grid:
for ϕ in search_grid:
current_val = state_action_values((s, ϕ), x, v) if s + ϕ <= 1 else -1
if current_val > max_val:
max_val = current_val
max_s, max_ϕ = s, ϕ
s_policy[i], ϕ_policy[i] = max_s, max_ϕ
return s_policy, ϕ_policy
return T, get_greedy
To solve the model, we will write a function that uses the Bellman operator and iterates to find a fixed point.
def solve_model(jv,
use_parallel=True,
tol=1e-4,
max_iter=1000,
verbose=True,
print_skip=25):
"""
Solves the model by value function iteration
* jv is an instance of JVWorker
"""
T, _ = operator_factory(jv, parallel_flag=use_parallel)
# Set up loop
v = jv.x_grid * 0.5 # Initial condition
i = 0
error = tol + 1
while i < max_iter and error > tol:
v_new = T(v)
error = np.max(np.abs(v - v_new))
i += 1
if verbose and i % print_skip == 0:
print(f"Error at iteration {i} is {error}.")
v = v_new
if error > tol:
print("Failed to converge!")
elif verbose:
print(f"\nConverged in {i} iterations.")
return v_new
56.4. Solving for Policies#
Let’s generate the optimal policies and see what they look like.
jv = JVWorker()
T, get_greedy = operator_factory(jv)
v_star = solve_model(jv)
s_star, ϕ_star = get_greedy(v_star)
Error at iteration 25 is 0.15111148060249047.
Error at iteration 50 is 0.0544600814630094.
Error at iteration 75 is 0.01962723455909199.
Error at iteration 100 is 0.00707359089610371.
Error at iteration 125 is 0.002549298935360156.
Error at iteration 150 is 0.0009187589665984319.
Error at iteration 175 is 0.0003311177151452682.
Error at iteration 200 is 0.00011933373743389097.
Converged in 205 iterations.
Here are the plots:
plots = [s_star, ϕ_star, v_star]
titles = ["s policy", "ϕ policy", "value function"]
fig, axes = plt.subplots(3, 1, figsize=(12, 12))
for ax, plot, title in zip(axes, plots, titles):
ax.plot(jv.x_grid, plot)
ax.set(title=title)
ax.grid()
axes[-1].set_xlabel("x")
plt.show()
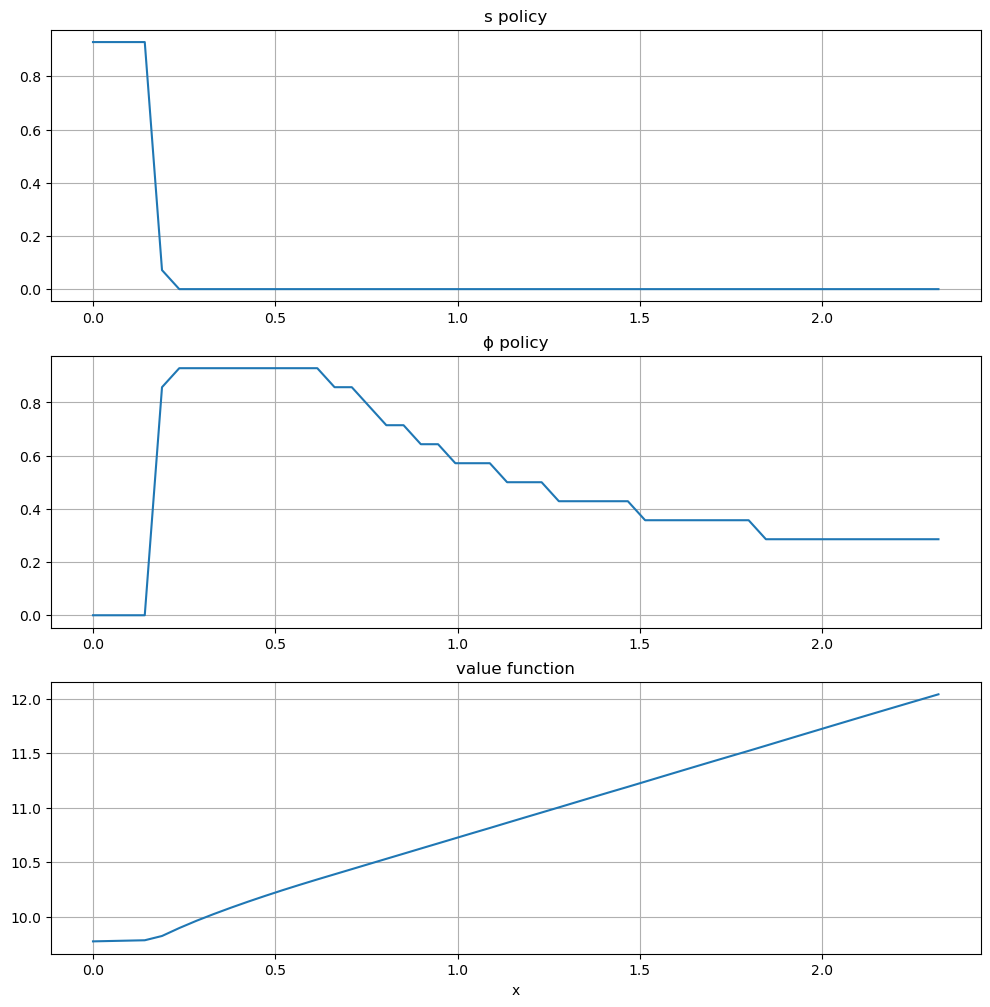
The horizontal axis is the state \(x\), while the vertical axis gives \(s(x)\) and \(\phi(x)\).
Overall, the policies match well with our predictions from above
Worker switches from one investment strategy to the other depending on relative return.
For low values of \(x\), the best option is to search for a new job.
Once \(x\) is larger, worker does better by investing in human capital specific to the current position.
56.5. Exercises#
Exercise 56.1
Let’s look at the dynamics for the state process \(\{x_t\}\) associated with these policies.
The dynamics are given by (56.1) when \(\phi_t\) and \(s_t\) are chosen according to the optimal policies, and \(\mathbb{P}\{b_{t+1} = 1\} = \pi(s_t)\).
Since the dynamics are random, analysis is a bit subtle.
One way to do it is to plot, for each \(x\) in a relatively fine grid
called plot_grid, a
large number \(K\) of realizations of \(x_{t+1}\) given \(x_t =
x\).
Plot this with one dot for each realization, in the form of a 45 degree diagram, setting
jv = JVWorker(grid_size=25, mc_size=50)
plot_grid_max, plot_grid_size = 1.2, 100
plot_grid = np.linspace(0, plot_grid_max, plot_grid_size)
fig, ax = plt.subplots()
ax.set_xlim(0, plot_grid_max)
ax.set_ylim(0, plot_grid_max)
By examining the plot, argue that under the optimal policies, the state \(x_t\) will converge to a constant value \(\bar x\) close to unity.
Argue that at the steady state, \(s_t \approx 0\) and \(\phi_t \approx 0.6\).
Solution
Here’s code to produce the 45 degree diagram
jv = JVWorker(grid_size=25, mc_size=50)
π, g, f_rvs, x_grid = jv.π, jv.g, jv.f_rvs, jv.x_grid
T, get_greedy = operator_factory(jv)
v_star = solve_model(jv, verbose=False)
s_policy, ϕ_policy = get_greedy(v_star)
# Turn the policy function arrays into actual functions
s = lambda y: np.interp(y, x_grid, s_policy)
ϕ = lambda y: np.interp(y, x_grid, ϕ_policy)
def h(x, b, u):
return (1 - b) * g(x, ϕ(x)) + b * max(g(x, ϕ(x)), u)
plot_grid_max, plot_grid_size = 1.2, 100
plot_grid = np.linspace(0, plot_grid_max, plot_grid_size)
fig, ax = plt.subplots(figsize=(8, 8))
ticks = (0.25, 0.5, 0.75, 1.0)
ax.set(xticks=ticks, yticks=ticks,
xlim=(0, plot_grid_max),
ylim=(0, plot_grid_max),
xlabel='$x_t$', ylabel='$x_{t+1}$')
ax.plot(plot_grid, plot_grid, 'k--', alpha=0.6) # 45 degree line
for x in plot_grid:
for i in range(jv.mc_size):
b = 1 if np.random.uniform(0, 1) < π(s(x)) else 0
u = f_rvs[i]
y = h(x, b, u)
ax.plot(x, y, 'go', alpha=0.25)
plt.show()
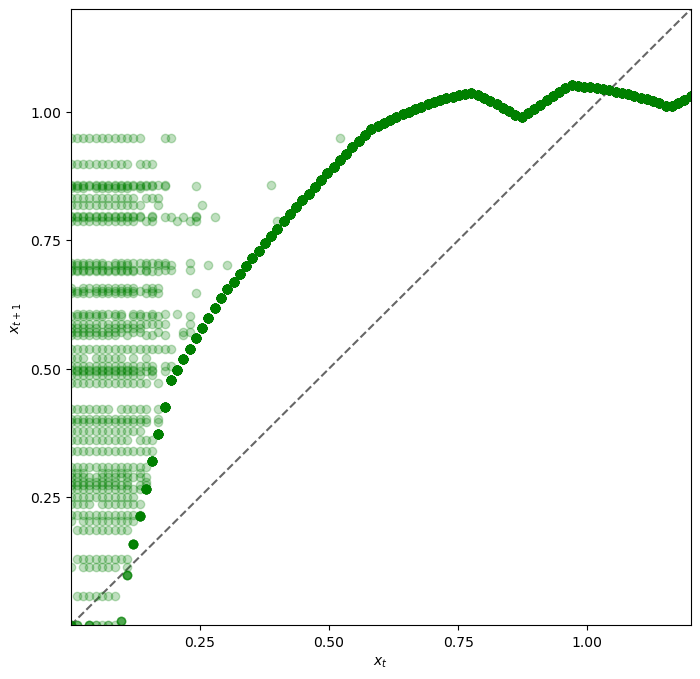
Looking at the dynamics, we can see that
If \(x_t\) is below about 0.2 the dynamics are random, but \(x_{t+1} > x_t\) is very likely.
As \(x_t\) increases the dynamics become deterministic, and \(x_t\) converges to a steady state value close to 1.
Referring back to the figure here we see that \(x_t \approx 1\) means that \(s_t = s(x_t) \approx 0\) and \(\phi_t = \phi(x_t) \approx 0.6\).
Exercise 56.2
In Exercise 56.1, we found that \(s_t\) converges to zero and \(\phi_t\) converges to about 0.6.
Since these results were calculated at a value of \(\beta\) close to one, let’s compare them to the best choice for an infinitely patient worker.
Intuitively, an infinitely patient worker would like to maximize steady state wages, which are a function of steady state capital.
You can take it as given—it’s certainly true—that the infinitely patient worker does not search in the long run (i.e., \(s_t = 0\) for large \(t\)).
Thus, given \(\phi\), steady state capital is the positive fixed point \(x^*(\phi)\) of the map \(x \mapsto g(x, \phi)\).
Steady state wages can be written as \(w^*(\phi) = x^*(\phi) (1 - \phi)\).
Graph \(w^*(\phi)\) with respect to \(\phi\), and examine the best choice of \(\phi\).
Can you give a rough interpretation for the value that you see?
Solution
The figure can be produced as follows
jv = JVWorker()
def xbar(ϕ):
A, α = jv.A, jv.α
return (A * ϕ**α)**(1 / (1 - α))
ϕ_grid = np.linspace(0, 1, 100)
fig, ax = plt.subplots(figsize=(9, 7))
ax.set(xlabel=r'$\phi$')
ax.plot(ϕ_grid, [xbar(ϕ) * (1 - ϕ) for ϕ in ϕ_grid], label=r'$w^*(\phi)$')
ax.legend()
plt.show()
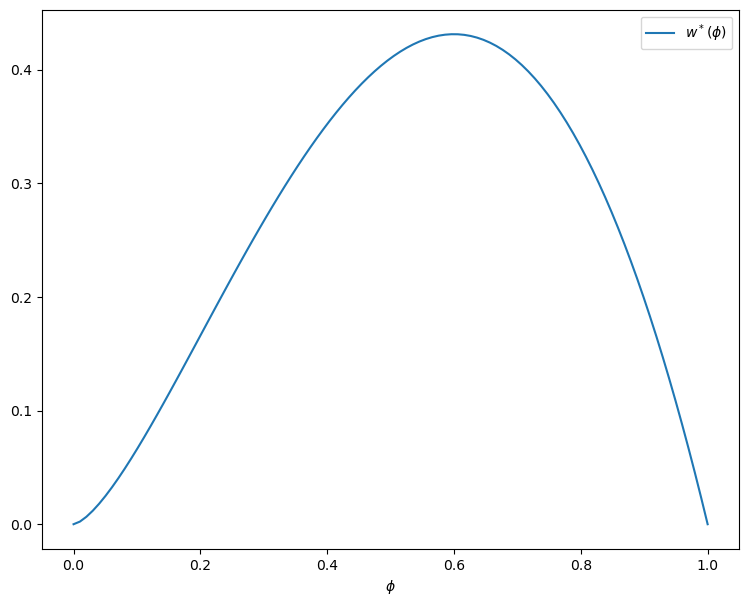
Observe that the maximizer is around 0.6.
This is similar to the long-run value for \(\phi\) obtained in Exercise 56.1.
Hence the behavior of the infinitely patent worker is similar to that of the worker with \(\beta = 0.96\).
This seems reasonable and helps us confirm that our dynamic programming solutions are probably correct.