60. Job Search IX: Search with Q-Learning#
60.1. Overview#
This lecture illustrates a powerful machine learning technique called Q-learning.
[Sutton and Barto, 2018] presents Q-learning and a variety of other statistical learning procedures.
The Q-learning algorithm combines ideas from
dynamic programming
a recursive version of least squares known as temporal difference learning.
This lecture applies a Q-learning algorithm to the situation faced by a McCall worker.
This lecture also considers the case where a McCall worker is given an option to quit the current job.
Relative to the dynamic programming formulation of the McCall worker model that we studied in quantecon lecture, a Q-learning algorithm gives the worker less knowledge about
the random process that generates a sequence of wages
the reward function that tells consequences of accepting or rejecting a job
The Q-learning algorithm invokes a statistical learning model to learn about these things.
Statistical learning often comes down to some version of least squares, and it will be here too.
Any time we say statistical learning, we have to say what object is being learned.
For Q-learning, the object that is learned is not the value function that is a focus of dynamic programming.
But it is something that is closely affiliated with it.
In the finite-action, finite state context studied in this lecture, the object to be learned statistically is a Q-table, an instance of a Q-function for finite sets.
Sometimes a Q-function or Q-table is called a quality-function or quality-table.
The rows and columns of a Q-table correspond to possible states that an agent might encounter, and possible actions that he can take in each state.
An equation that resembles a Bellman equation plays an important role in the algorithm.
It differs from the Bellman equation for the McCall model that we have seen in this quantecon lecture
In this lecture, we’ll learn a little about
the Q-function or quality function that is affiliated with any Markov decision problem whose optimal value function satisfies a Bellman equation
temporal difference learning, a key component of a Q-learning algorithm
As usual, let’s import some Python modules.
!pip install quantecon
import numpy as np
from numba import jit, float64, int64
from numba.experimental import jitclass
from quantecon.distributions import BetaBinomial
import matplotlib.pyplot as plt
np.random.seed(123)
60.2. Review of McCall Model#
We begin by reviewing the McCall model described in this quantecon lecture.
We’ll compute an optimal value function and a policy that attains it.
We’ll eventually compare that optimal policy to what the Q-learning McCall worker learns.
The McCall model is characterized by parameters \(\beta,c\) and a known distribution of wage offers \(F\).
A McCall worker wants to maximize an expected discounted sum of lifetime incomes
The worker’s income \(y_t\) equals his wage \(w\) if he is employed, and unemployment compensation \(c\) if he is unemployed.
An optimal value \(V\left(w\right) \) for a McCall worker who has just received a wage offer \(w\) and is deciding whether to accept or reject it satisfies the Bellman equation
To form a benchmark to compare with results from Q-learning, we first approximate the optimal value function.
With possible states residing in a finite discrete state space indexed by \(\{1,2,...,n\}\), we make an initial guess for the value function of \(v\in\mathbb{R}^{n}\) and then iterate on the Bellman equation:
Let’s use Python code from this quantecon lecture.
We use a Python method called VFI to compute the optimal value function using value function iterations.
We construct an assumed distribution of wages and plot it with the following Python code
n, a, b = 10, 200, 100 # default parameters
q_default = BetaBinomial(n, a, b).pdf() # default choice of q
w_min, w_max = 10, 60
w_default = np.linspace(w_min, w_max, n+1)
# plot distribution of wage offer
fig, ax = plt.subplots(figsize=(10,6))
ax.plot(w_default, q_default, '-o', label='$q(w(i))$')
ax.set_xlabel('wages')
ax.set_ylabel('probabilities')
plt.show()
Next we’ll compute the worker’s optimal value function by iterating to convergence on the Bellman equation.
Then we’ll plot various iterates on the Bellman operator.
mccall_data = [
('c', float64), # unemployment compensation
('β', float64), # discount factor
('w', float64[::1]), # array of wage values, w[i] = wage at state i
('q', float64[::1]) # array of probabilities
]
@jitclass(mccall_data)
class McCallModel:
def __init__(self, c=25, β=0.99, w=w_default, q=q_default):
self.c, self.β = c, β
self.w, self.q = w, q
def state_action_values(self, i, v):
"""
The values of state-action pairs.
"""
# Simplify names
c, β, w, q = self.c, self.β, self.w, self.q
# Evaluate value for each state-action pair
# Consider action = accept or reject the current offer
accept = w[i] / (1 - β)
reject = c + β * (v @ q)
return np.array([accept, reject])
def VFI(self, eps=1e-5, max_iter=500):
"""
Find the optimal value function.
"""
n = len(self.w)
v = self.w / (1 - self.β)
v_next = np.empty_like(v)
flag=0
for i in range(max_iter):
for j in range(n):
v_next[j] = np.max(self.state_action_values(j, v))
if np.max(np.abs(v_next - v))<=eps:
flag=1
break
v[:] = v_next
return v, flag
def plot_value_function_seq(mcm, ax, num_plots=8):
"""
Plot a sequence of value functions.
* mcm is an instance of McCallModel
* ax is an axes object that implements a plot method.
"""
n = len(mcm.w)
v = mcm.w / (1 - mcm.β)
v_next = np.empty_like(v)
for i in range(num_plots):
ax.plot(mcm.w, v, '-', alpha=0.4, label=f"iterate {i}")
# Update guess
for i in range(n):
v_next[i] = np.max(mcm.state_action_values(i, v))
v[:] = v_next # copy contents into v
ax.legend(loc='lower right')
mcm = McCallModel()
valfunc_VFI, flag = mcm.VFI()
fig, ax = plt.subplots(figsize=(10,6))
ax.set_xlabel('wage')
ax.set_ylabel('value')
plot_value_function_seq(mcm, ax)
plt.show()
Next we’ll print out the limit of the sequence of iterates.
This is the approximation to the McCall worker’s value function that is produced by value function iteration.
We’ll use this value function as a benchmark later after we have done some Q-learning.
print(valfunc_VFI)
[5322.27935875 5322.27935875 5322.27935875 5322.27935875 5322.27935875
5322.27935875 5322.27935875 5322.27935875 5322.27935875 5500.
6000. ]
60.3. Implied Quality Function \(Q\)#
A quality function \(Q\) map state-action pairs into optimal values.
They are tightly linked to optimal value functions.
But value functions are functions just of states, and not actions.
For each given state, the quality function gives a list of optimal values that can be attained starting from that state, with each component of the list indicating one of the possible actions that is taken.
For our McCall worker with a finite set of possible wages
the state space \(\mathcal{W}=\{w_1,w_2,...,w_n\}\) is indexed by integers \(1,2,...,n\)
the action space is \(\mathcal{A}=\{\text{accept}, \text{reject}\}\)
Let \(a \in \mathcal{A}\) be one of the two possible actions, i.e., accept or reject.
For our McCall worker, an optimal Q-function \(Q(w,a)\) equals the maximum value of that a previously unemployed worker who has offer \(w\) in hand can attain if he takes action \(a\).
This definition of \(Q(w,a)\) presumes that in subsequent periods the worker takes optimal actions.
An optimal Q-function for our McCall worker satisfies
Note that the first equation of system (60.2) presumes that after the agent has accepted an offer, he will not have the objection to reject that same offer in the future.
These equations are aligned with the Bellman equation for the worker’s optimal value function that we studied in this quantecon lecture.
Evidently, the optimal value function \(V(w)\) described in that lecture is related to our Q-function by
If we stare at the second equation of system (60.2), we notice that since the wage process is identically and independently distributed over time, \(Q\left(w,\text{reject}\right)\), the right side of the equation is independent of the current state \(w\).
So we can denote it as a scalar
This fact provides us with an an alternative, and as it turns out in this case, a faster way to compute an optimal value function and associated optimal policy for the McCall worker.
Instead of using the value function iterations that we deployed above, we can instead iterate to convergence on a version of the second equation in system (60.2) that maps an estimate of \(Q_r\) into an improved estimate \(Q_r'\):
After a \(Q_r\) sequence has converged, we can recover the optimal value function \(V(w)\) for the McCall worker from
60.4. From Probabilities to Samples#
We noted above that the optimal Q function for our McCall worker satisfies the Bellman equations
Notice the integral over \(F(w')\) on the second line.
Erasing the integral sign sets the stage for an illegitmate argument that can get us started thinking about Q-learning.
Thus, construct a difference equation system that keeps the first equation of (60.3) but replaces the second by removing integration over \(F (w')\):
The second equation can’t hold for all \(w, w'\) pairs in the appropriate Cartesian product of our state space.
But maybe an appeal to a Law of Large numbers could let us hope that it would hold on average for a long time series sequence of draws of \(w_t, w_{t+1}\) pairs, where we are thinking of \(w_t\) as \(w\) and \(w_{t+1}\) as \(w'\).
The basic idea of Q-learning is to draw a long sample of wage offers from \(F\) (we know \(F\) though we assume that the worker doesn’t) and iterate on a recursion that maps an estimate \(\hat Q_t\) of a Q-function at date \(t\) into an improved estimate \(\hat Q_{t+1}\) at date \(t+1\).
To set up such an algorithm, we first define some errors or “differences”
The adaptive learning scheme would then be some version of
where \(\alpha \in (0,1)\) is a small gain parameter that governs the rate of learning and \(\hat Q_t\) and \(\textrm{diff}_t\) are \(2 \times 1\) vectors corresponding to objects in equation system (60.5).
This informal argument takes us to the threshold of Q-learning.
60.5. Q-Learning#
Let’s first describe a \(Q\)-learning algorithm precisely.
Then we’ll implement it.
The algorithm works by using a Monte Carlo method to update estimates of a Q-function.
We begin with an initial guess for a Q-function.
In the example studied in this lecture, we have a finite action space and also a finite state space.
That means that we can represent a Q-function as a matrix or Q-table, \(\widetilde{Q}(w,a)\).
Q-learning proceeds by updating the Q-function as the decision maker acquires experience along a path of wage draws generated by simulation.
During the learning process, our McCall worker takes actions and experiences rewards that are consequences of those actions.
He learns simultaneously about the environment, in this case the distribution of wages, and the reward function, in this case the unemployment compensation \(c\) and the present value of wages.
The updating algorithm is based on a slight modification (to be described soon) of a recursion like
where
The terms \(\widetilde{TD}(w,a) \) for \(a = \left\{\textrm{accept,reject} \right\}\) are the temporal difference errors that drive the updates.
This system is thus a version of the adaptive system that we sketched informally in equation (60.6).
An aspect of the algorithm not yet captured by equation system (60.8) is random experimentation that we add by occasionally randomly replacing
with
and occasionally replacing
with
We activate such experimentation with probability \(\epsilon\) in step 3 of the following pseudo-code for our McCall worker to do Q-learning:
Set an arbitrary initial Q-table.
Draw an initial wage offer \(w\) from \(F\).
From the appropriate row in the Q-table, choose an action using the following \(\epsilon\)-greedy algorithm:
with probability \(1-\epsilon\), choose the action that maximizes the value, and
with probability \(\epsilon\), choose the alternative action.
Update the state associated with the chosen action and compute \(\widetilde{TD}\) according to (60.8) and update \(\widetilde{Q}\) according to (60.7).
Either draw a new state \(w'\) if required or else take existing wage if and update the Q-table again according to (60.7).
Stop when the old and new Q-tables are close enough, i.e., \(\lVert\tilde{Q}^{new}-\tilde{Q}^{old}\rVert_{\infty}\leq\delta\) for given \(\delta\) or if the worker keeps accepting for \(T\) periods for a prescribed \(T\).
Return to step 2 with the updated Q-table.
Repeat this procedure for \(N\) episodes or until the updated Q-table has converged.
We call one pass through steps 2 to 7 an “episode” or “epoch” of temporal difference learning.
In our context, each episode starts with an agent drawing an initial wage offer, i.e., a new state.
The agent then takes actions based on the preset Q-table, receives rewards, and then enters a new state implied by this period’s actions.
The Q-table is updated via temporal difference learning.
We iterate this until convergence of the Q-table or the maximum length of an episode is reached.
Multiple episodes allow the agent to start afresh and visit states that she was less likely to visit from the terminal state of a previos episode.
For example, an agent who has accepted a wage offer based on her Q-table will be less likely to draw a new offer from other parts of the wage distribution.
By using the \(\epsilon\)-greedy method and also by increasing the number of episodes, the Q-learning algorithm balances gains from exploration and from exploitation.
Remark: Notice that \(\widetilde{TD}\) associated with an optimal Q-table defined in (60.7) automatically above satisfies \(\widetilde{TD}=0\) for all state action pairs. Whether a limit of our Q-learning algorithm converges to an optimal Q-table depends on whether the algorithm visits all state-action pairs often enough.
We implement this pseudo code in a Python class.
For simplicity and convenience, we let s represent the state index between \(0\) and \(n=50\) and \(w_s=w[s]\).
The first column of the Q-table represents the value associated with rejecting the wage and the second represents accepting the wage.
We use numba compilation to accelerate computations.
params=[
('c', float64), # unemployment compensation
('β', float64), # discount factor
('w', float64[:]), # array of wage values, w[i] = wage at state i
('q', float64[:]), # array of probabilities
('eps', float64), # for epsilon greedy algorithm
('δ', float64), # Q-table threshold
('lr', float64), # the learning rate α
('T', int64), # maximum periods of accepting
('quit_allowed', int64) # whether quit is allowed after accepting the wage offer
]
@jitclass(params)
class Qlearning_McCall:
def __init__(self, c=25, β=0.99, w=w_default, q=q_default, eps=0.1,
δ=1e-5, lr=0.5, T=10000, quit_allowed=0):
self.c, self.β = c, β
self.w, self.q = w, q
self.eps, self.δ, self.lr, self.T = eps, δ, lr, T
self.quit_allowed = quit_allowed
def draw_offer_index(self):
"""
Draw a state index from the wage distribution.
"""
q = self.q
return np.searchsorted(np.cumsum(q), np.random.random(), side="right")
def temp_diff(self, qtable, state, accept):
"""
Compute the TD associated with state and action.
"""
c, β, w = self.c, self.β, self.w
if accept==0:
state_next = self.draw_offer_index()
TD = c + β*np.max(qtable[state_next, :]) - qtable[state, accept]
else:
state_next = state
if self.quit_allowed == 0:
TD = w[state_next] + β*np.max(qtable[state_next, :]) - qtable[state, accept]
else:
TD = w[state_next] + β*qtable[state_next, 1] - qtable[state, accept]
return TD, state_next
def run_one_epoch(self, qtable, max_times=20000):
"""
Run an "epoch".
"""
c, β, w = self.c, self.β, self.w
eps, δ, lr, T = self.eps, self.δ, self.lr, self.T
s0 = self.draw_offer_index()
s = s0
accept_count = 0
for t in range(max_times):
# choose action
accept = np.argmax(qtable[s, :])
if np.random.random()<=eps:
accept = 1 - accept
if accept == 1:
accept_count += 1
else:
accept_count = 0
TD, s_next = self.temp_diff(qtable, s, accept)
# update qtable
qtable_new = qtable.copy()
qtable_new[s, accept] = qtable[s, accept] + lr*TD
if np.max(np.abs(qtable_new-qtable))<=δ:
break
if accept_count == T:
break
s, qtable = s_next, qtable_new
return qtable_new
@jit
def run_epochs(N, qlmc, qtable):
"""
Run epochs N times with qtable from the last iteration each time.
"""
for n in range(N):
if n%(N/10)==0:
print(f"Progress: EPOCHs = {n}")
new_qtable = qlmc.run_one_epoch(qtable)
qtable = new_qtable
return qtable
def valfunc_from_qtable(qtable):
return np.max(qtable, axis=1)
def compute_error(valfunc, valfunc_VFI):
return np.mean(np.abs(valfunc-valfunc_VFI))
# create an instance of Qlearning_McCall
qlmc = Qlearning_McCall()
# run
qtable0 = np.zeros((len(w_default), 2))
qtable = run_epochs(20000, qlmc, qtable0)
Progress: EPOCHs = 0
Progress: EPOCHs = 2000
Progress: EPOCHs = 4000
Progress: EPOCHs = 6000
Progress: EPOCHs = 8000
Progress: EPOCHs = 10000
Progress: EPOCHs = 12000
Progress: EPOCHs = 14000
Progress: EPOCHs = 16000
Progress: EPOCHs = 18000
print(qtable)
[[4927.22816485 0. ]
[5289.16407066 5282.12139665]
[5261.21319217 5227.68466161]
[5315.77199059 5244.3958654 ]
[5371.06169823 5207.31543458]
[5291.87006491 5264.5462269 ]
[5267.37397452 5293.88469861]
[5608.84086085 5251.3579503 ]
[5286.85728385 5285.97690201]
[5335.05293637 5500.00000948]
[5479.37334525 6000. ]]
# inspect value function
valfunc_qlr = valfunc_from_qtable(qtable)
print(valfunc_qlr)
[4927.22816485 5289.16407066 5261.21319217 5315.77199059 5371.06169823
5291.87006491 5293.88469861 5608.84086085 5286.85728385 5500.00000948
6000. ]
# plot
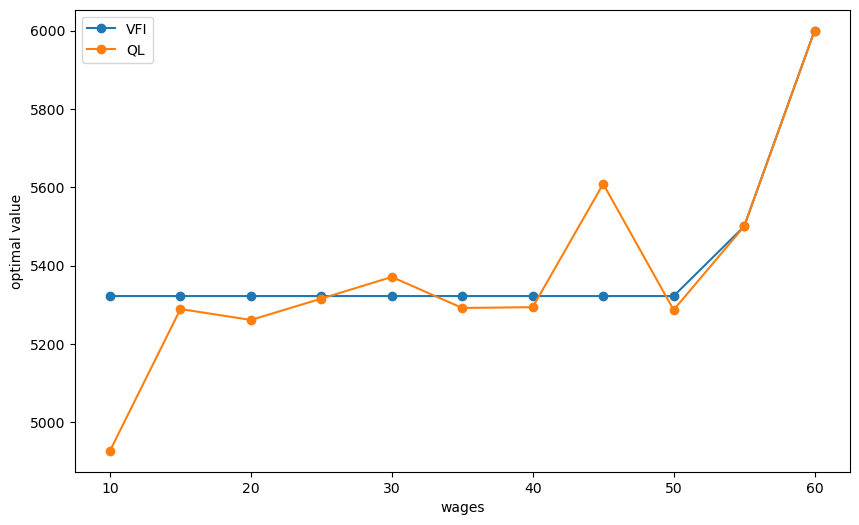
fig, ax = plt.subplots(figsize=(10,6))
ax.plot(w_default, valfunc_VFI, '-o', label='VFI')
ax.plot(w_default, valfunc_qlr, '-o', label='QL')
ax.set_xlabel('wages')
ax.set_ylabel('optimal value')
ax.legend()
plt.show()
Now, let us compute the case with a larger state space: \(n=30\) instead of \(n=10\).
n, a, b = 30, 200, 100 # default parameters
q_new = BetaBinomial(n, a, b).pdf() # default choice of q
w_min, w_max = 10, 60
w_new = np.linspace(w_min, w_max, n+1)
# plot distribution of wage offer
fig, ax = plt.subplots(figsize=(10,6))
ax.plot(w_new, q_new, '-o', label='$q(w(i))$')
ax.set_xlabel('wages')
ax.set_ylabel('probabilities')
plt.show()
# VFI
mcm = McCallModel(w=w_new, q=q_new)
valfunc_VFI, flag = mcm.VFI()
mcm = McCallModel(w=w_new, q=q_new)
valfunc_VFI, flag = mcm.VFI()
valfunc_VFI
array([4859.77015703, 4859.77015703, 4859.77015703, 4859.77015703,
4859.77015703, 4859.77015703, 4859.77015703, 4859.77015703,
4859.77015703, 4859.77015703, 4859.77015703, 4859.77015703,
4859.77015703, 4859.77015703, 4859.77015703, 4859.77015703,
4859.77015703, 4859.77015703, 4859.77015703, 4859.77015703,
4859.77015703, 4859.77015703, 4859.77015703, 4859.77015703,
5000. , 5166.66666667, 5333.33333333, 5500. ,
5666.66666667, 5833.33333333, 6000. ])
def plot_epochs(epochs_to_plot, quit_allowed=1):
"Plot value function implied by outcomes of an increasing number of epochs."
qlmc_new = Qlearning_McCall(w=w_new, q=q_new, quit_allowed=quit_allowed)
qtable = np.zeros((len(w_new),2))
epochs_to_plot = np.asarray(epochs_to_plot)
# plot
fig, ax = plt.subplots(figsize=(10,6))
ax.plot(w_new, valfunc_VFI, '-o', label='VFI')
max_epochs = np.max(epochs_to_plot)
# iterate on epoch numbers
for n in range(max_epochs + 1):
if n%(max_epochs/10)==0:
print(f"Progress: EPOCHs = {n}")
if n in epochs_to_plot:
valfunc_qlr = valfunc_from_qtable(qtable)
error = compute_error(valfunc_qlr, valfunc_VFI)
ax.plot(w_new, valfunc_qlr, '-o', label=f'QL:epochs={n}, mean error={error}')
new_qtable = qlmc_new.run_one_epoch(qtable)
qtable = new_qtable
ax.set_xlabel('wages')
ax.set_ylabel('optimal value')
ax.legend(loc='lower right')
plt.show()
plot_epochs(epochs_to_plot=[100, 1000, 10000, 100000, 200000])
Progress: EPOCHs = 0
Progress: EPOCHs = 20000
Progress: EPOCHs = 40000
Progress: EPOCHs = 60000
Progress: EPOCHs = 80000
Progress: EPOCHs = 100000
Progress: EPOCHs = 120000
Progress: EPOCHs = 140000
Progress: EPOCHs = 160000
Progress: EPOCHs = 180000
Progress: EPOCHs = 200000
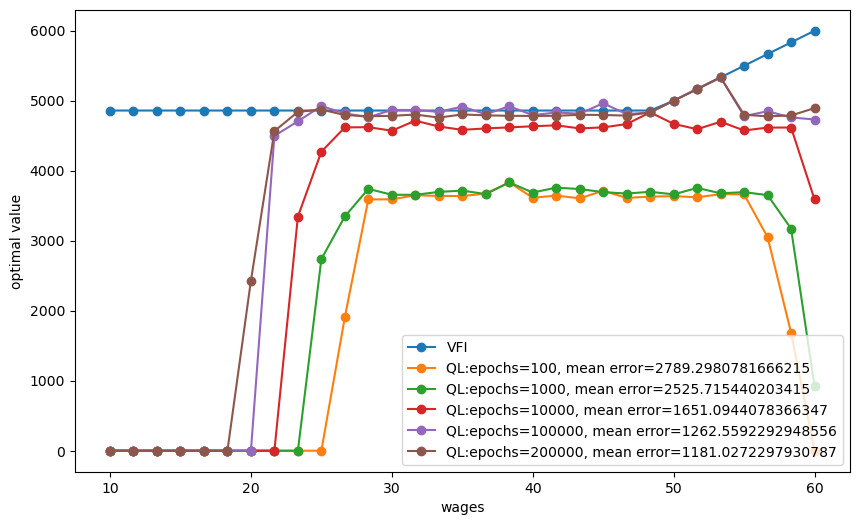
The above graphs indicates that
the Q-learning algorithm has trouble learning the Q-table well for wages that are rarely drawn
the quality of approximation to the “true” value function computed by value function iteration improves for longer epochs
60.6. Employed Worker Can’t Quit#
The preceding version of temporal difference Q-learning described in equation system (60.8) lets an employed worker quit, i.e., reject her wage as an incumbent and instead receive unemployment compensation this period and draw a new offer next period.
This is an option that the McCall worker described in this quantecon lecture would not take.
See [Ljungqvist and Sargent, 2018], chapter 6 on search, for a proof.
But in the context of Q-learning, giving the worker the option to quit and get unemployment compensation while unemployed turns out to accelerate the learning process by promoting experimentation vis a vis premature exploitation only.
To illustrate this, we’ll amend our formulas for temporal differences to forbid an employed worker from quitting a job she had accepted earlier.
With this understanding about available choices, we obtain the following temporal difference values:
It turns out that formulas (60.9) combined with our Q-learning recursion (60.7) can lead our agent to eventually learn the optimal value function as well as in the case where an option to redraw can be exercised.
But learning is slower because an agent who ends up accepting a wage offer prematurally loses the option to explore new states in the same episode and to adjust the value associated with that state.
This can lead to inferior outcomes when the number of epochs/episodes is low.
But if we increase the number of epochs/episodes, we can observe that the error decreases and the outcomes get better.
We illustrate these possibilities with the following code and graph.
plot_epochs(epochs_to_plot=[100, 1000, 10000, 100000, 200000], quit_allowed=0)
Progress: EPOCHs = 0
Progress: EPOCHs = 20000
Progress: EPOCHs = 40000
Progress: EPOCHs = 60000
Progress: EPOCHs = 80000
Progress: EPOCHs = 100000
Progress: EPOCHs = 120000
Progress: EPOCHs = 140000
Progress: EPOCHs = 160000
Progress: EPOCHs = 180000
Progress: EPOCHs = 200000
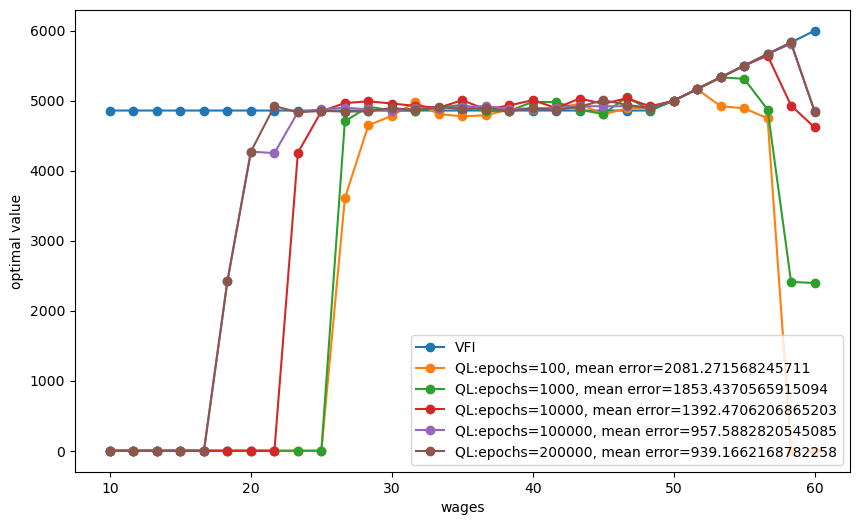
60.7. Possible Extensions#
To extend the algorthm to handle problems with continuous state spaces, a typical approach is to restrict Q-functions and policy functions to take particular functional forms.
This is the approach in deep Q-learning where the idea is to use a multilayer neural network as a good function approximator.
We will take up this topic in a subsequent quantecon lecture.