97. Asset Pricing: Finite State Models#
“A little knowledge of geometric series goes a long way” – Robert E. Lucas, Jr.
“Asset pricing is all about covariances” – Lars Peter Hansen
In addition to what’s in Anaconda, this lecture will need the following libraries:
!pip install quantecon
97.1. Overview#
An asset is a claim on one or more future payoffs.
The spot price of an asset depends primarily on
the anticipated income stream
attitudes about risk
rates of time preference
In this lecture, we consider some standard pricing models and dividend stream specifications.
We study how prices and dividend-price ratios respond in these different scenarios.
We also look at creating and pricing derivative assets that repackage income streams.
Key tools for the lecture are
Markov processses
formulas for predicting future values of functions of a Markov state
a formula for predicting the discounted sum of future values of a Markov state
Let’s start with some imports:
import matplotlib.pyplot as plt
import numpy as np
import quantecon as qe
from numpy.linalg import eigvals, solve
97.2. Pricing Models#
Let \(\{d_t\}_{t \geq 0}\) be a stream of dividends
A time-\(t\) cum-dividend asset is a claim to the stream \(d_t, d_{t+1}, \ldots\).
A time-\(t\) ex-dividend asset is a claim to the stream \(d_{t+1}, d_{t+2}, \ldots\).
Let’s look at some equations that we expect to hold for prices of assets under ex-dividend contracts (we will consider cum-dividend pricing in the exercises).
97.2.1. Risk-Neutral Pricing#
Our first scenario is risk-neutral pricing.
Let \(\beta = 1/(1+\rho)\) be an intertemporal discount factor, where \(\rho\) is the rate at which agents discount the future.
The basic risk-neutral asset pricing equation for pricing one unit of an ex-dividend asset is
This is a simple “cost equals expected benefit” relationship.
Here \({\mathbb E}_t [y]\) denotes the best forecast of \(y\), conditioned on information available at time \(t\).
More precisely, \({\mathbb E}_t [y]\) is the mathematical expectation of \(y\) conditional on information available at time \(t\).
97.2.2. Pricing with Random Discount Factor#
What happens if for some reason traders discount payouts differently depending on the state of the world?
Michael Harrison and David Kreps [Harrison and Kreps, 1979] and Lars Peter Hansen and Scott Richard [Hansen and Richard, 1987] showed that in quite general settings the price of an ex-dividend asset obeys
for some stochastic discount factor \(m_{t+1}\).
Here the fixed discount factor \(\beta\) in (97.1) has been replaced by the random variable \(m_{t+1}\).
How anticipated future payoffs are evaluated now depends on statistical properties of \(m_{t+1}\).
The stochastic discount factor can be specified to capture the idea that assets that tend to have good payoffs in bad states of the world are valued more highly than other assets whose payoffs don’t behave that way.
This is because such assets pay well when funds are more urgently wanted.
We give examples of how the stochastic discount factor has been modeled below.
97.2.3. Asset Pricing and Covariances#
Recall that, from the definition of a conditional covariance \({\rm cov}_t (x_{t+1}, y_{t+1})\), we have
If we apply this definition to the asset pricing equation (97.2) we obtain
It is useful to regard equation (97.4) as a generalization of equation (97.1)
In equation (97.1), the stochastic discount factor \(m_{t+1} = \beta\), a constant.
In equation (97.1), the covariance term \({\rm cov}_t (m_{t+1}, d_{t+1}+ p_{t+1})\) is zero because \(m_{t+1} = \beta\).
In equation (97.1), \({\mathbb E}_t m_{t+1}\) can be interpreted as the reciprocal of the one-period risk-free gross interest rate.
When \(m_{t+1}\) covaries more negatively with the payout \(p_{t+1} + d_{t+1}\), the price of the asset is lower.
Equation (97.4) asserts that the covariance of the stochastic discount factor with the one period payout \(d_{t+1} + p_{t+1}\) is an important determinant of the price \(p_t\).
We give examples of some models of stochastic discount factors that have been proposed later in this lecture and also in a later lecture.
97.2.4. The Price-Dividend Ratio#
Aside from prices, another quantity of interest is the price-dividend ratio \(v_t := p_t / d_t\).
Let’s write down an expression that this ratio should satisfy.
We can divide both sides of (97.2) by \(d_t\) to get
Below we’ll discuss the implication of this equation.
97.3. Prices in the Risk-Neutral Case#
What can we say about price dynamics on the basis of the models described above?
The answer to this question depends on
the process we specify for dividends
the stochastic discount factor and how it correlates with dividends
For now we’ll study the risk-neutral case in which the stochastic discount factor is constant.
We’ll focus on how an asset price depends on a dividend process.
97.3.1. Example 1: Constant Dividends#
The simplest case is risk-neutral price of a constant, non-random dividend stream \(d_t = d > 0\).
Removing the expectation from (97.1) and iterating forward gives
If \(\lim_{k \rightarrow + \infty} \beta^{k-1} p_{t+k} = 0\), this sequence converges to
This is the equilibrium price in the constant dividend case.
Indeed, simple algebra shows that setting \(p_t = \bar p\) for all \(t\) satisfies the difference equation \(p_t = \beta (d + p_{t+1})\).
97.3.2. Example 2: Dividends with Deterministic Growth Paths#
Consider a growing, non-random dividend process \(d_{t+1} = g d_t\) where \(0 < g \beta < 1\).
While prices are not usually constant when dividends grow over time, a price dividend-ratio can be.
If we guess this, substituting \(v_t = v\) into (97.5) as well as our other assumptions, we get \(v = \beta g (1 + v)\).
Since \(\beta g < 1\), we have a unique positive solution:
The price is then
If, in this example, we take \(g = 1+\kappa\) and let \(\rho := 1/\beta - 1\), then the price becomes
This is called the Gordon formula.
97.3.3. Example 3: Markov Growth, Risk-Neutral Pricing#
Next, we consider a dividend process
The stochastic growth factor \(\{g_t\}\) is given by
where
\(\{X_t\}\) is a finite Markov chain with state space \(S\) and transition probabilities
\[ P(x, y) := \mathbb P \{ X_{t+1} = y \,|\, X_t = x \} \qquad (x, y \in S) \]\(g\) is a given function on \(S\) taking nonnegative values
You can think of
\(S\) as \(n\) possible “states of the world” and \(X_t\) as the current state.
\(g\) as a function that maps a given state \(X_t\) into a growth of dividends factor \(g_t = g(X_t)\).
\(\ln g_t = \ln (d_{t+1} / d_t)\) is the growth rate of dividends.
(For a refresher on notation and theory for finite Markov chains see this lecture)
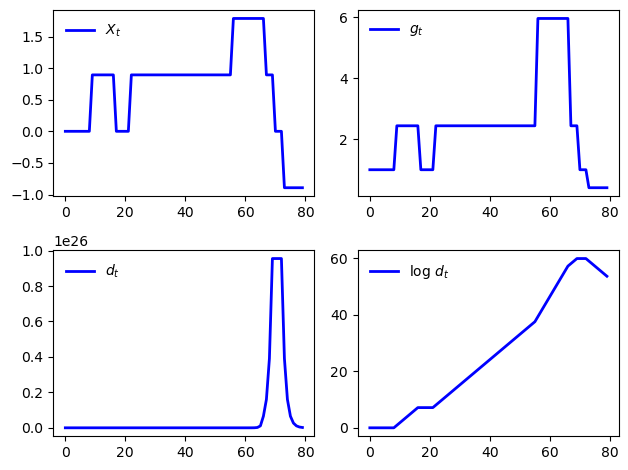
The next figure shows a simulation, where
\(\{X_t\}\) evolves as a discretized AR1 process produced using Tauchen’s method.
\(g_t = \exp(X_t)\), so that \(\ln g_t = X_t\) is the growth rate.
n = 7
mc = qe.tauchen(n, 0.96, 0.25)
sim_length = 80
x_series = mc.simulate(sim_length, init=np.median(mc.state_values))
g_series = np.exp(x_series)
d_series = np.cumprod(g_series) # Assumes d_0 = 1
series = [x_series, g_series, d_series, np.log(d_series)]
labels = ['$X_t$', '$g_t$', '$d_t$', r'$\log \, d_t$']
fig, axes = plt.subplots(2, 2)
for ax, s, label in zip(axes.flatten(), series, labels):
ax.plot(s, 'b-', lw=2, label=label)
ax.legend(loc='upper left', frameon=False)
plt.tight_layout()
plt.show()
97.3.3.1. Pricing Formula#
To obtain asset prices in this setting, let’s adapt our analysis from the case of deterministic growth.
In that case, we found that \(v\) is constant.
This encourages us to guess that, in the current case, \(v_t\) is a fixed function of the state \(X_t\).
We seek a function \(v\) such that the price-dividend ratio satisfies \(v_t = v(X_t)\).
We can substitute this guess into (97.5) to get
If we condition on \(X_t = x\), this becomes
or
Suppose that there are \(n\) possible states \(x_1, \ldots, x_n\).
We can then think of (97.8) as \(n\) stacked equations, one for each state, and write it in matrix form as
Here
\(v\) is understood to be the column vector \((v(x_1), \ldots, v(x_n))'\).
\(K\) is the matrix \((K(x_i, x_j))_{1 \leq i, j \leq n}\).
\({\mathbb 1}\) is a column vector of ones.
When does equation (97.9) have a unique solution?
From the Neumann series lemma and Gelfand’s formula, equation (97.9) has a unique solution when \(\beta K\) has spectral radius strictly less than one.
Thus, we require that the eigenvalues of \(K\) be strictly less than \(\beta^{-1}\) in modulus.
The solution is then
97.3.4. Code#
Let’s calculate and plot the price-dividend ratio at some parameters.
As before, we’ll generate \(\{X_t\}\) as a discretized AR1 process and set \(g_t = \exp(X_t)\).
Here’s the code, including a test of the spectral radius condition
n = 25 # Size of state space
β = 0.9
mc = qe.tauchen(n, 0.96, 0.02)
K = mc.P * np.exp(mc.state_values)
warning_message = "Spectral radius condition fails"
assert np.max(np.abs(eigvals(K))) < 1 / β, warning_message
I = np.identity(n)
v = solve(I - β * K, β * K @ np.ones(n))
fig, ax = plt.subplots()
ax.plot(mc.state_values, v, 'g-o', lw=2, alpha=0.7, label='$v$')
ax.set_ylabel("price-dividend ratio")
ax.set_xlabel("state")
ax.legend(loc='upper left')
plt.show()
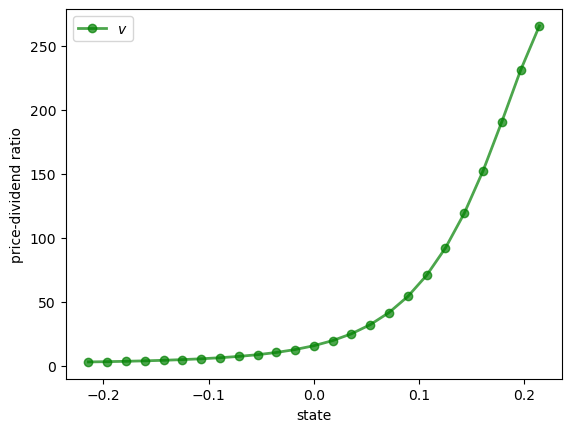
Why does the price-dividend ratio increase with the state?
The reason is that this Markov process is positively correlated, so high current states suggest high future states.
Moreover, dividend growth is increasing in the state.
The anticipation of high future dividend growth leads to a high price-dividend ratio.
97.4. Risk Aversion and Asset Prices#
Now let’s turn to the case where agents are risk averse.
We’ll price several distinct assets, including
An endowment stream
A consol (a type of bond issued by the UK government in the 19th century)
Call options on a consol
97.4.1. Pricing a Lucas Tree#
Let’s start with a version of the celebrated asset pricing model of Robert E. Lucas, Jr. [Lucas, 1978].
Lucas considered an abstract pure exchange economy with these features:
a single non-storable consumption good
a Markov process that governs the total amount of the consumption good available each period
a single tree that each period yields fruit that equals the total amount of consumption available to the economy
a competitive market in shares in the tree that entitles their owners to corresponding shares of the dividend stream, i.e., the fruit stream, yielded by the tree
a representative consumer who in a competitive equilibrium
consumes the economy’s entire endowment each period
owns 100 percent of the shares in the tree
As in [Lucas, 1978], we suppose that the stochastic discount factor takes the form
where \(u\) is a concave utility function and \(c_t\) is time \(t\) consumption of a representative consumer.
(A derivation of this expression is given in a later lecture)
Assume the existence of an endowment that follows growth process (97.7).
The asset being priced is a claim on the endowment process, i.e., the Lucas tree described above.
Following [Lucas, 1978], we suppose that in equilibrium the representative consumer’s consumption equals the aggregate endowment, so that \(d_t = c_t\) for all \(t\).
For utility, we’ll assume the constant relative risk aversion (CRRA) specification
When \(\gamma =1\) we let \(u(c) = \ln c\).
Inserting the CRRA specification into (97.11) and using \(c_t = d_t\) gives
Substituting this into (97.5) gives the price-dividend ratio formula
Conditioning on \(X_t = x\), we can write this as
If we let
then we can rewrite equation (97.14) in vector form as
Assuming that the spectral radius of \(J\) is strictly less than \(\beta^{-1}\), this equation has the unique solution
We will define a function tree_price to compute \(v\) given parameters stored in the class AssetPriceModel
class AssetPriceModel:
"""
A class that stores the primitives of the asset pricing model.
Parameters
----------
β : scalar, float
Discount factor
mc : MarkovChain
Contains the transition matrix and set of state values for the state
process
γ : scalar(float)
Coefficient of risk aversion
g : callable
The function mapping states to growth rates
"""
def __init__(self, β=0.96, mc=None, γ=2.0, g=np.exp):
self.β, self.γ = β, γ
self.g = g
# A default process for the Markov chain
if mc is None:
self.ρ = 0.9
self.σ = 0.02
self.mc = qe.tauchen(n, self.ρ, self.σ)
else:
self.mc = mc
self.n = self.mc.P.shape[0]
def test_stability(self, Q):
"""
Stability test for a given matrix Q.
"""
sr = np.max(np.abs(eigvals(Q)))
if not sr < 1 / self.β:
msg = f"Spectral radius condition failed with radius = {sr}"
raise ValueError(msg)
def tree_price(ap):
"""
Computes the price-dividend ratio of the Lucas tree.
Parameters
----------
ap: AssetPriceModel
An instance of AssetPriceModel containing primitives
Returns
-------
v : array_like(float)
Lucas tree price-dividend ratio
"""
# Simplify names, set up matrices
β, γ, P, y = ap.β, ap.γ, ap.mc.P, ap.mc.state_values
J = P * ap.g(y)**(1 - γ)
# Make sure that a unique solution exists
ap.test_stability(J)
# Compute v
I = np.identity(ap.n)
Ones = np.ones(ap.n)
v = solve(I - β * J, β * J @ Ones)
return v
Here’s a plot of \(v\) as a function of the state for several values of \(\gamma\), with a positively correlated Markov process and \(g(x) = \exp(x)\)
γs = [1.2, 1.4, 1.6, 1.8, 2.0]
ap = AssetPriceModel()
states = ap.mc.state_values
fig, ax = plt.subplots()
for γ in γs:
ap.γ = γ
v = tree_price(ap)
ax.plot(states, v, lw=2, alpha=0.6, label=rf"$\gamma = {γ}$")
ax.set_title('Price-dividend ratio as a function of the state')
ax.set_ylabel("price-dividend ratio")
ax.set_xlabel("state")
ax.legend(loc='upper right')
plt.show()
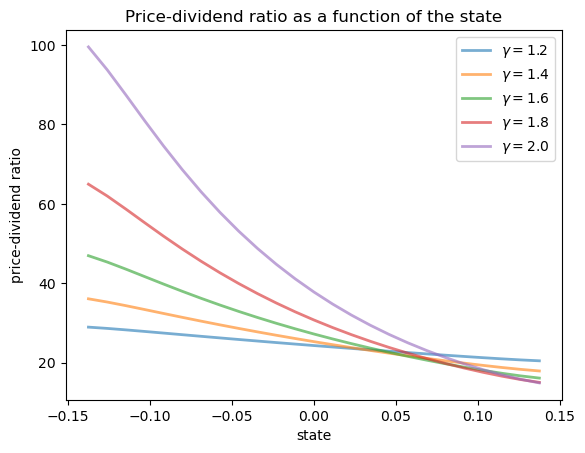
Notice that \(v\) is decreasing in each case.
This is because, with a positively correlated state process, higher states indicate higher future consumption growth.
With the stochastic discount factor (97.13), higher growth decreases the discount factor, lowering the weight placed on future dividends.
97.4.1.1. Special Cases#
In the special case \(\gamma =1\), we have \(J = P\).
Recalling that \(P^i {\mathbb 1} = {\mathbb 1}\) for all \(i\) and applying Neumann’s geometric series lemma, we are led to
Thus, with log preferences, the price-dividend ratio for a Lucas tree is constant.
Alternatively, if \(\gamma = 0\), then \(J = K\) and we recover the risk-neutral solution (97.10).
This is as expected, since \(\gamma = 0\) implies \(u(c) = c\) (and hence agents are risk-neutral).
97.4.2. A Risk-Free Consol#
Consider the same pure exchange representative agent economy.
A risk-free consol promises to pay a constant amount \(\zeta> 0\) each period.
Recycling notation, let \(p_t\) now be the price of an ex-coupon claim to the consol.
An ex-coupon claim to the consol entitles an owner at the end of period \(t\) to
\(\zeta\) in period \(t+1\), plus
the right to sell the claim for \(p_{t+1}\) next period
The price satisfies (97.2) with \(d_t = \zeta\), or
With the stochastic discount factor (97.13), this becomes
Guessing a solution of the form \(p_t = p(X_t)\) and conditioning on \(X_t = x\), we get
Letting \(M(x, y) = P(x, y) g(y)^{-\gamma}\) and rewriting in vector notation yields the solution
The above is implemented in the function consol_price.
def consol_price(ap, ζ):
"""
Computes price of a consol bond with payoff ζ
Parameters
----------
ap: AssetPriceModel
An instance of AssetPriceModel containing primitives
ζ : scalar(float)
Coupon of the console
Returns
-------
p : array_like(float)
Console bond prices
"""
# Simplify names, set up matrices
β, γ, P, y = ap.β, ap.γ, ap.mc.P, ap.mc.state_values
M = P * ap.g(y)**(- γ)
# Make sure that a unique solution exists
ap.test_stability(M)
# Compute price
I = np.identity(ap.n)
Ones = np.ones(ap.n)
p = solve(I - β * M, β * ζ * M @ Ones)
return p
97.4.3. Pricing an Option to Purchase the Consol#
Let’s now price options of various maturities.
We’ll study an option that gives the owner the right to purchase a consol at a price \(p_S\).
97.4.3.1. An Infinite Horizon Call Option#
We want to price an infinite horizon option to purchase a consol at a price \(p_S\).
The option entitles the owner at the beginning of a period either
to purchase the bond at price \(p_S\) now, or
not to exercise the option to purchase the asset now but to retain the right to exercise it later
Thus, the owner either exercises the option now or chooses not to exercise and wait until next period.
This is termed an infinite-horizon call option with strike price \(p_S\).
The owner of the option is entitled to purchase the consol at price \(p_S\) at the beginning of any period, after the coupon has been paid to the previous owner of the bond.
The fundamentals of the economy are identical with the one above, including the stochastic discount factor and the process for consumption.
Let \(w(X_t, p_S)\) be the value of the option when the time \(t\) growth state is known to be \(X_t\) but before the owner has decided whether to exercise the option at time \(t\) (i.e., today).
Recalling that \(p(X_t)\) is the value of the consol when the initial growth state is \(X_t\), the value of the option satisfies
The first term on the right is the value of waiting, while the second is the value of exercising now.
We can also write this as
With \(M(x, y) = P(x, y) g(y)^{-\gamma}\) and \(w\) as the vector of values \((w(x_i), p_S)_{i = 1}^n\), we can express (97.18) as the nonlinear vector equation
To solve (97.19), form an operator \(T\) that maps vector \(w\) into vector \(Tw\) via
Start at some initial \(w\) and iterate with \(T\) to convergence .
We can find the solution with the following function call_option
def call_option(ap, ζ, p_s, ϵ=1e-7):
"""
Computes price of a call option on a consol bond.
Parameters
----------
ap: AssetPriceModel
An instance of AssetPriceModel containing primitives
ζ : scalar(float)
Coupon of the console
p_s : scalar(float)
Strike price
ϵ : scalar(float), optional(default=1e-8)
Tolerance for infinite horizon problem
Returns
-------
w : array_like(float)
Infinite horizon call option prices
"""
# Simplify names, set up matrices
β, γ, P, y = ap.β, ap.γ, ap.mc.P, ap.mc.state_values
M = P * ap.g(y)**(- γ)
# Make sure that a unique consol price exists
ap.test_stability(M)
# Compute option price
p = consol_price(ap, ζ)
w = np.zeros(ap.n)
error = ϵ + 1
while error > ϵ:
# Maximize across columns
w_new = np.maximum(β * M @ w, p - p_s)
# Find maximal difference of each component and update
error = np.amax(np.abs(w - w_new))
w = w_new
return w
Here’s a plot of \(w\) compared to the consol price when \(P_S = 40\)
ap = AssetPriceModel(β=0.9)
ζ = 1.0
strike_price = 40
x = ap.mc.state_values
p = consol_price(ap, ζ)
w = call_option(ap, ζ, strike_price)
fig, ax = plt.subplots()
ax.plot(x, p, 'b-', lw=2, label='consol price')
ax.plot(x, w, 'g-', lw=2, label='value of call option')
ax.set_xlabel("state")
ax.legend(loc='upper right')
plt.show()
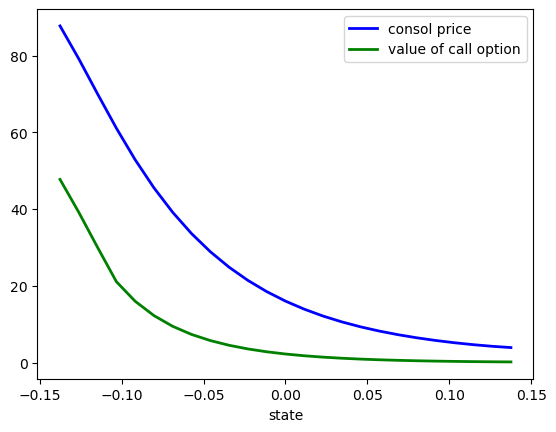
In high values of the Markov growth state, the value of the option is close to zero.
This is despite the facts that the Markov chain is irreducible and that low states — where the consol prices are high — will be visited recurrently.
The reason for low valuations in high Markov growth states is that \(\beta=0.9\), so future payoffs are discounted substantially.
97.4.4. Risk-Free Rates#
Let’s look at risk-free interest rates over different periods.
97.4.4.1. The One-period Risk-free Interest Rate#
As before, the stochastic discount factor is \(m_{t+1} = \beta g_{t+1}^{-\gamma}\).
It follows that the reciprocal \(R_t^{-1}\) of the gross risk-free interest rate \(R_t\) in state \(x\) is
We can write this as
where the \(i\)-th element of \(m_1\) is the reciprocal of the one-period gross risk-free interest rate in state \(x_i\).
97.4.4.2. Other Terms#
Let \(m_j\) be an \(n \times 1\) vector whose \(i\) th component is the reciprocal of the \(j\) -period gross risk-free interest rate in state \(x_i\).
Then \(m_1 = \beta M\), and \(m_{j+1} = M m_j\) for \(j \geq 1\).
97.5. Exercises#
Exercise 97.1
In the lecture, we considered ex-dividend assets.
A cum-dividend asset is a claim to the stream \(d_t, d_{t+1}, \ldots\).
Following (97.1), find the risk-neutral asset pricing equation for one unit of a cum-dividend asset.
With a constant, non-random dividend stream \(d_t = d > 0\), what is the equilibrium price of a cum-dividend asset?
With a growing, non-random dividend process \(d_t = g d_t\) where \(0 < g \beta < 1\), what is the equilibrium price of a cum-dividend asset?
Solution
For a cum-dividend asset, the basic risk-neutral asset pricing equation is
With constant dividends, the equilibrium price is
With a growing, non-random dividend process, the equilibrium price is
Exercise 97.2
Consider the following primitives
n = 5 # Size of State Space
P = np.full((n, n), 0.0125)
P[range(n), range(n)] += 1 - P.sum(1)
# State values of the Markov chain
s = np.array([0.95, 0.975, 1.0, 1.025, 1.05])
γ = 2.0
β = 0.94
Let \(g\) be defined by \(g(x) = x\) (that is, \(g\) is the identity map).
Compute the price of the Lucas tree.
Do the same for
the price of the risk-free consol when \(\zeta = 1\)
the call option on the consol when \(\zeta = 1\) and \(p_S = 150.0\)
Solution
First, let’s enter the parameters:
n = 5
P = np.full((n, n), 0.0125)
P[range(n), range(n)] += 1 - P.sum(1)
s = np.array([0.95, 0.975, 1.0, 1.025, 1.05]) # State values
mc = qe.MarkovChain(P, state_values=s)
γ = 2.0
β = 0.94
ζ = 1.0
p_s = 150.0
Next, we’ll create an instance of AssetPriceModel to feed into the
functions
apm = AssetPriceModel(β=β, mc=mc, γ=γ, g=lambda x: x)
Now we just need to call the relevant functions on the data:
tree_price(apm)
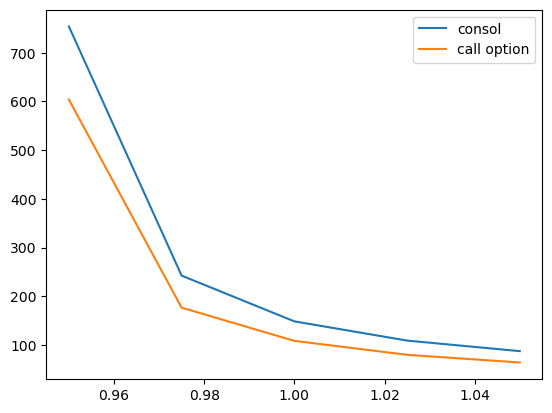
array([29.47401578, 21.93570661, 17.57142236, 14.72515002, 12.72221763])
consol_price(apm, ζ)
array([753.87100476, 242.55144082, 148.67554548, 109.25108965,
87.56860139])
call_option(apm, ζ, p_s)
array([603.87100476, 176.8393343 , 108.67734499, 80.05179254,
64.30843748])
Let’s show the last two functions as a plot
fig, ax = plt.subplots()
ax.plot(s, consol_price(apm, ζ), label='consol')
ax.plot(s, call_option(apm, ζ, p_s), label='call option')
ax.legend()
plt.show()
Exercise 97.3
Let’s consider finite horizon call options, which are more common than infinite horizon ones.
Finite horizon options obey functional equations closely related to (97.18).
A \(k\) period option expires after \(k\) periods.
If we view today as date zero, a \(k\) period option gives the owner the right to exercise the option to purchase the risk-free consol at the strike price \(p_S\) at dates \(0, 1, \ldots , k-1\).
The option expires at time \(k\).
Thus, for \(k=1, 2, \ldots\), let \(w(x, k)\) be the value of a \(k\)-period option.
It obeys
where \(w(x, 0) = 0\) for all \(x\).
We can express this as a sequence of nonlinear vector equations
Write a function that computes \(w_k\) for any given \(k\).
Compute the value of the option with k = 5 and k = 25 using parameter values as in Exercise 97.1.
Is one higher than the other? Can you give intuition?
Solution
Here’s a suitable function:
def finite_horizon_call_option(ap, ζ, p_s, k):
"""
Computes k period option value.
"""
# Simplify names, set up matrices
β, γ, P, y = ap.β, ap.γ, ap.mc.P, ap.mc.state_values
M = P * ap.g(y)**(- γ)
# Make sure that a unique solution exists
ap.test_stability(M)
# Compute option price
p = consol_price(ap, ζ)
w = np.zeros(ap.n)
for i in range(k):
# Maximize across columns
w = np.maximum(β * M @ w, p - p_s)
return w
Now let’s compute the option values at k=5 and k=25
fig, ax = plt.subplots()
for k in [5, 25]:
w = finite_horizon_call_option(apm, ζ, p_s, k)
ax.plot(s, w, label=rf'$k = {k}$')
ax.legend()
plt.show()
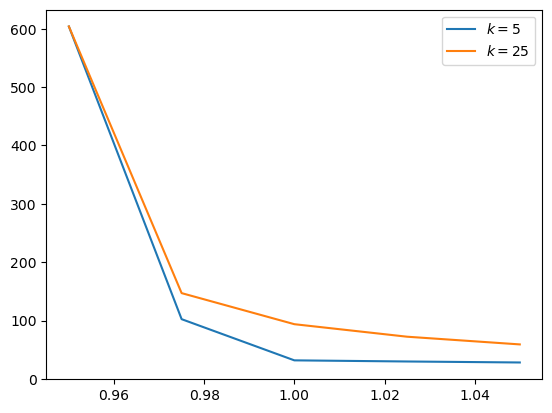
Not surprisingly, options with larger \(k\) are worth more.
This is because an owner has a longer horizon over which the option can be exercised.