45. A First Look at the Kalman Filter#
In addition to what’s in Anaconda, this lecture will need the following libraries:
!pip install quantecon
45.1. Overview#
This lecture provides a simple and intuitive introduction to the Kalman filter
It is aimed at readers who either
have heard of the Kalman filter but don’t know how it works, or
know the Kalman filter equations, but don’t know where they come from
Subsequent lectures use the same recursive logic in more applied and more econometric settings.
See Another Look at the Kalman Filter for an economic application in which a firm infers a worker’s hidden human capital and effort.
See The Kalman Filter and Vector Autoregressions for a derivation of the innovations representation and its connection to vector autoregressions.
For additional (more advanced) reading on the Kalman filter, see
[Ljungqvist and Sargent, 2018], section 2.7
The second reference presents a comprehensive treatment of the Kalman filter.
Required knowledge: Familiarity with matrix manipulations, multivariate normal distributions, covariance matrices, etc.
We’ll need the following imports:
import matplotlib.pyplot as plt
from scipy import linalg
import numpy as np
from quantecon import Kalman, LinearStateSpace
from scipy.stats import norm, multivariate_normal
from scipy.integrate import quad
from scipy.linalg import eigvals
45.2. The basic idea#
The Kalman filter has many applications in economics, but for now let’s pretend that we are rocket scientists.
A missile has been launched from a hostile country and our mission is to track it.
Let \(X_t \in \mathbb{R}^2\) denote the current location of the missile—a pair indicating latitude-longitude coordinates on a map.
At the present moment in time, the location \(X_t\) is unknown, but we do have some beliefs about it.
We could certainly produce a point prediction.
For example, it could mark a point on the globe somewhere in northern Mongolia.
But the fact is that we are uncertain.
And the President wants to know: what is the probability that the missile is within 500km of Manhattan?
A point prediction doesn’t address that question.
Hence it’s best if we can express our current understanding via a bivariate probability density \(p\).
Now \(\int_E p(x)dx\) indicates the probability that the missile is in region \(E\).
We will call \(p\) our prior for the random variable \(X\).
To keep things tractable, we assume for now that our prior is Gaussian.
In particular, we take
where \(\mu\) is the (vector) mean of the distribution—a natural point prediction—and \(\Sigma\) is a \(2 \times 2\) covariance matrix.
In our simulations, we will suppose that
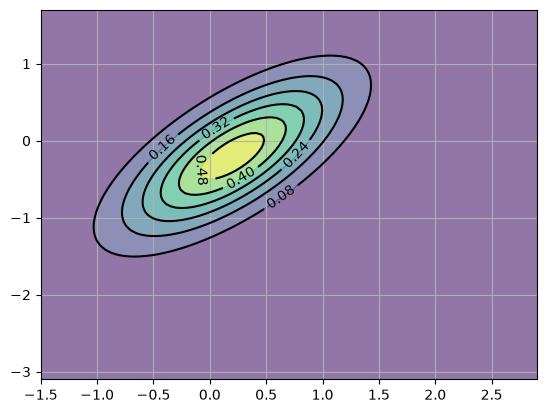
This density \(p\) is shown below as a contour map, with the center of the red ellipse being equal to \(\mu\).
# Set up the Gaussian prior density p
Σ = np.array([[0.4, 0.3],
[0.3, 0.45]])
μ = np.array([[0.2],
[-0.2]])
# Define the matrices G and R from the measurement equation Y = G X + v
G = np.array([[1, 0],
[0, 1]])
R = 0.5 * Σ
# The matrices A and Q
A = np.array([[1.2, 0],
[0, -0.2]])
Q = 0.3 * Σ
# The observed value of y
y = np.array([[2.3],
[-1.9]])
# Set up grid for plotting
x_grid = np.linspace(-1.5, 2.9, 100)
y_grid = np.linspace(-3.1, 1.7, 100)
X, Y = np.meshgrid(x_grid, y_grid)
def gen_gaussian_plot_vals(μ, C):
"Z values for plotting the bivariate Gaussian N(μ, C)"
pos = np.dstack((X, Y))
return multivariate_normal(μ.ravel(), C).pdf(pos)
# Plot the figure
fig, ax = plt.subplots()
ax.grid()
Z = gen_gaussian_plot_vals(μ, Σ)
ax.contourf(X, Y, Z, 6, alpha=0.6, cmap="viridis")
cs = ax.contour(X, Y, Z, 6, colors="black")
ax.clabel(cs, inline=1, fontsize=10)
plt.show()
45.2.1. The filtering step#
We are now presented with some good news and some bad news.
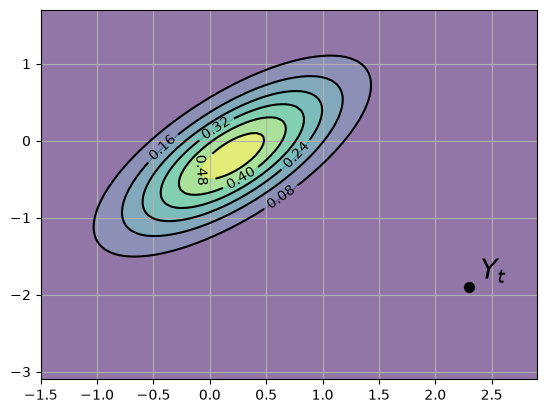
The good news is that the missile has been located by our sensors, which report that the current location is \(Y_t = (2.3, -1.9)\).
The next figure shows the original prior \(p\) and the new reported signal \(Y_t\)
fig, ax = plt.subplots()
ax.grid()
Z = gen_gaussian_plot_vals(μ, Σ)
ax.contourf(X, Y, Z, 6, alpha=0.6, cmap="viridis")
cs = ax.contour(X, Y, Z, 6, colors="black")
ax.clabel(cs, inline=1, fontsize=10)
y_1, y_2 = y[0].item(), y[1].item()
ax.scatter(y_1, y_2, marker="o", s=50, color="black", zorder=3)
ax.text(y_1 + 0.1, y_2 + 0.1, "$Y_t$", fontsize=20, color="black")
plt.show()
The bad news is that our sensors are imprecise.
The sensor report is a noisy signal distorted by measurement error.
In particular, we should interpret the output of our sensor not as \(Y_t=X_t\), but rather as
Here \(G\) and \(R\) are \(2 \times 2\) matrices, with \(R\) being symmetric and positive definite.
We assume that
\(G\) and \(R\) are known
the noise term \(v_t\) is unobservable and independent of \(X_t\)
How then should we combine our prior \(X_t \sim N(\mu, \Sigma)\) and this new information \(Y_t\) to improve our understanding of the location of the missile?
As you may have guessed, the answer is to use Bayes’ theorem.
It tells us how to update the prior density \(p(x)\) for \(X_t\) to the posterior density \(p(x \,|\, y)\) after observing \(Y_t\):
where \(p(Y_t) = \int p(Y_t \,|\, x) \, p(x) dx\).
In solving for \(p(x \,|\, Y_t)\), we observe that
\(p(x)\) is the prior density \(N(\mu, \Sigma)\).
\(p(Y_t \,|\, x)\) is the conditional density of \(Y_t\) given \(X_t=x\).
In view of (45.3), this conditional density is \(N(Gx, R)\).
Due to our linear Gaussian framework, the updated density turns out to be Gaussian as well.
In particular, the solution is known to be
where
and
Note
A proof can be found in [Bishop, 2006].
To get from his expressions to the ones used above, you will also need to apply the Woodbury matrix identity.
Here \(\Sigma G^\top (G \Sigma G^\top + R)^{-1}\) is the matrix of population regression coefficients of the hidden state deviation \(X_t - \mu\) on the signal surprise \(Y_t - G \mu\).
This new density \(p(x \,|\, Y_t) = N(\mu^F, \Sigma^F)\) is shown in the next figure via contour lines and the color map.
The original density is left in as contour lines for comparison
fig, ax = plt.subplots()
ax.grid()
Z = gen_gaussian_plot_vals(μ, Σ)
cs1 = ax.contour(X, Y, Z, 6, colors="black")
ax.clabel(cs1, inline=1, fontsize=10)
M = Σ @ G.T @ linalg.inv(G @ Σ @ G.T + R)
μ_F = μ + M @ (y - G @ μ)
Σ_F = Σ - M @ G @ Σ
new_Z = gen_gaussian_plot_vals(μ_F, Σ_F)
cs2 = ax.contour(X, Y, new_Z, 6, colors="black")
ax.clabel(cs2, inline=1, fontsize=10)
ax.contourf(X, Y, new_Z, 6, alpha=0.6, cmap="viridis")
y_1, y_2 = y[0].item(), y[1].item()
ax.scatter(y_1, y_2, marker="o", s=50, color="black", zorder=3)
ax.text(y_1 + 0.1, y_2 + 0.1, "$Y_t$", fontsize=20, color="black")
plt.show()
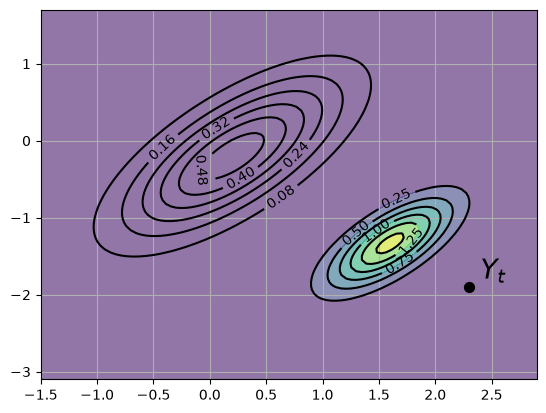
Our new density twists the prior \(p(x)\) in a direction determined by the new information \(Y_t - G \mu\).
In generating the figure, we set \(G\) to the identity matrix and \(R = 0.5 \Sigma\) for \(\Sigma\) defined in (45.2).
45.2.2. The forecast step#
What have we achieved so far?
We have obtained probabilities for the current location of the state (missile) given prior and current information.
This is called “filtering” rather than forecasting because we are filtering out noise rather than looking into the future.
The posterior \(p(x \,|\, Y_t) = N(\mu^F, \Sigma^F)\) is called the filtering distribution for \(X_t\) after observing \(Y_t\)
But now let’s suppose that we are given another task: to predict the location of the missile after one unit of time (whatever that may be) has elapsed.
To do this we need a model of how the state evolves.
Let’s suppose that we have one, and that it’s linear and Gaussian.
In particular,
Our aim is to combine this law of motion and our current filtering distribution \(N(\mu^F, \Sigma^F)\) to come up with a new predictive distribution for the location in one unit of time.
In view of (45.6), all we have to do is introduce a random vector \(X^F \sim N(\mu^F, \Sigma^F)\) and work out the distribution of \(A X^F + W\) where \(W\) is independent of \(X^F\) and has distribution \(N(0, Q)\).
Since linear combinations of Gaussians are Gaussian, \(A X^F + W\) is Gaussian.
Standard calculations and the expressions in (45.4)–(45.5) tell us that
and
The matrix \(A \Sigma G^\top (G \Sigma G^\top + R)^{-1}\) is often written as \(K_{\Sigma}\) and called the Kalman gain.
The subscript \(\Sigma\) has been added to remind us that \(K_{\Sigma}\) depends on \(\Sigma\), but not \(Y_t\) or \(\mu\).
Using this notation, we can summarize our results as follows.
Our updated prediction is the density \(N(\mu_{\mathrm{new}}, \Sigma_{\mathrm{new}})\) where
The density \(p_{\mathrm{new}}(x) = N(\mu_{\mathrm{new}}, \Sigma_{\mathrm{new}})\) is called the predictive distribution
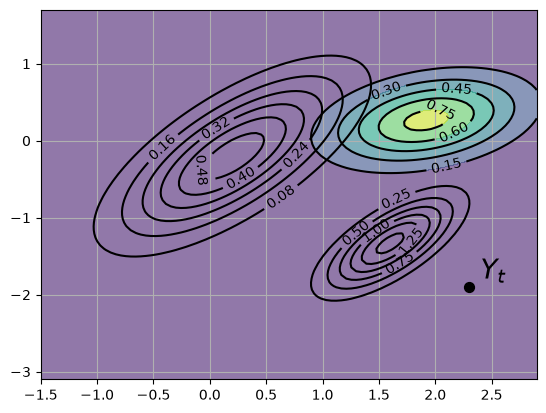
The predictive distribution is the new density shown in the following figure, where the update has used parameters.
fig, ax = plt.subplots()
ax.grid()
# Density 1
Z = gen_gaussian_plot_vals(μ, Σ)
cs1 = ax.contour(X, Y, Z, 6, colors="black")
ax.clabel(cs1, inline=1, fontsize=10)
# Density 2
M = Σ @ G.T @ linalg.inv(G @ Σ @ G.T + R)
μ_F = μ + M @ (y - G @ μ)
Σ_F = Σ - M @ G @ Σ
Z_F = gen_gaussian_plot_vals(μ_F, Σ_F)
cs2 = ax.contour(X, Y, Z_F, 6, colors="black")
ax.clabel(cs2, inline=1, fontsize=10)
# Density 3
new_μ = A @ μ_F
new_Σ = A @ Σ_F @ A.T + Q
new_Z = gen_gaussian_plot_vals(new_μ, new_Σ)
cs3 = ax.contour(X, Y, new_Z, 6, colors="black")
ax.clabel(cs3, inline=1, fontsize=10)
ax.contourf(X, Y, new_Z, 6, alpha=0.6, cmap="viridis")
y_1, y_2 = y[0].item(), y[1].item()
ax.scatter(y_1, y_2, marker="o", s=50, color="black", zorder=3)
ax.text(y_1 + 0.1, y_2 + 0.1, "$Y_t$", fontsize=20, color="black")
plt.show()
45.2.3. The recursive procedure#
Let’s look back at what we’ve done.
We started the current period with a prior density \(p_t(x)\) for the hidden state \(X_t\).
We then observed the signal \(Y_t\) and updated the prior density to the filtering density \(p_t(x \,|\, Y_t)\).
Finally, we used the law of motion (45.6) for \(\{X_t\}\) to update to the predictive density \(p_{t+1}(x)\) for \(X_{t+1}\).
If we now step into the next period, we are ready to go round again, taking \(p_{t+1}(x)\) as the current prior density and reading in the new observation \(Y_{t+1}\).
Using this time-indexed notation, the full recursive procedure is:
Start the current period with prior density \(p_t(x) = N(\mu_t, \Sigma_t)\) for \(X_t\).
Observe current signal \(Y_t = y_t\).
Compute the filtering density \(p_t(x \,|\, y_t) = N(\mu_t^F, \Sigma_t^F)\) from \(p_t(x)\) and \(y_t\), applying Bayes rule and the conditional distribution (45.3).
Compute the predictive density \(p_{t+1}(x) = N(\mu_{t+1}, \Sigma_{t+1})\) for \(X_{t+1}\) from the filtering density and (45.6).
Increment \(t\) by one and go to step 1.
Repeating (45.7), the dynamics for \(\mu_t\) and \(\Sigma_t\) are as follows
These are the standard dynamic equations for the Kalman filter (see, for example, [Ljungqvist and Sargent, 2018], page 58).
Note
Here \(\mu_t\) is the filter’s prediction of the hidden state \(X_t\).
In much of the Kalman filter literature it is written \(\hat x_t\), emphasizing that it is an estimate of \(X_t\).
45.3. Convergence#
The matrix \(\Sigma_t\) is a measure of the uncertainty of our prediction \(\mu_t\) of \(X_t\).
Apart from special cases, this uncertainty will never be fully resolved, regardless of how much time elapses.
One reason is that our prediction \(\mu_t\) is made based on information available at \(t-1\), not \(t\).
Even if we knew the precise realized value \(X_{t-1}=x_{t-1}\) (which we don’t), the transition equation (45.6) implies that \(X_t = A x_{t-1} + W_t\).
Since the shock \(W_t\) is not observable at \(t-1\), any time \(t-1\) prediction of \(X_t\) will incur some error (unless \(W_t\) is degenerate).
However, it is certainly possible that \(\Sigma_t\) converges to a constant matrix as \(t \to \infty\).
To study this topic, let’s expand the second equation in (45.8):
This is a nonlinear difference equation in \(\Sigma_t\).
A fixed point of (45.9) is a constant matrix \(\Sigma\) such that
Equation (45.9) is known as a discrete-time Riccati difference equation.
Equation (45.10) is known as a discrete-time algebraic Riccati equation.
Conditions under which a fixed point exists and the sequence \(\{\Sigma_t\}\) converges to it are discussed in [Anderson et al., 1996] and [Anderson and Moore, 2005], chapter 4.
A sufficient (but not necessary) condition is that all the eigenvalues \(\lambda_i\) of \(A\) satisfy \(|\lambda_i| < 1\).
See, for example, [Anderson and Moore, 2005], p. 77.
(This strong condition assures that the unconditional distribution of \(X_t\) converges as \(t \to \infty\).)
In this case, for any symmetric nonnegative definite initial choice of \(\Sigma_0\), the sequence \(\{\Sigma_t\}\) in (45.9) converges to a nonnegative symmetric matrix \(\Sigma\) that solves (45.10).
45.4. Implementation#
The class Kalman from the QuantEcon.py package implements the Kalman filter
Instance data consists of:
the moments \((\mu_t, \Sigma_t)\) of the current prior, stored as the attributes
x_hatandSigma(the mean \(\mu_t\) is namedx_hatbecause it is also written \(\hat x_t\) in much of the literature).An instance of the LinearStateSpace class from QuantEcon.py.
The latter represents a linear state space model of the form
where \(X_t\) and \(Y_t\) denote random variables, and the shocks \(w_t\) and \(v_t\) are IID standard normals.
To connect this with the notation of this lecture we set
The class
Kalmanfrom the QuantEcon.py package has a number of methods, some that we will wait to use until we study more advanced applications in subsequent lectures.Methods pertinent for this lecture are:
prior_to_filtered, which updates \((\mu_t, \Sigma_t)\) to \((\mu_t^F, \Sigma_t^F)\)filtered_to_forecast, which updates the filtering distribution to the predictive distribution – which becomes the new prior \((\mu_{t+1}, \Sigma_{t+1})\)update, which combines the last two methodsa
stationary_values, which computes the solution to (45.10) and the corresponding (stationary) Kalman gain
You can view the program on GitHub.
45.5. Exercises#
Exercise 45.1
Consider the following simple application of the Kalman filter, loosely based on [Ljungqvist and Sargent, 2018], section 2.9.2.
Suppose that
all variables are scalars
the hidden state \(\{X_t\}\) is in fact constant, equal to some \(\theta \in \mathbb{R}\) unknown to the modeler
State dynamics are therefore given by (45.6) with \(A=1\), \(Q=0\) and \(X_0 = \theta\).
The measurement equation is \(Y_t = \theta + v_t\) where \(v_t\) is \(N(0,1)\) and IID.
The task of this exercise is to simulate the model and, using the code from kalman.py, plot the first five predictive densities \(p_t(x) = N(\mu_t, \Sigma_t)\) for \(X_t\).
As shown in [Ljungqvist and Sargent, 2018], sections 2.9.1–2.9.2, these distributions asymptotically put all mass on the unknown value \(\theta\).
In the simulation, take \(\theta = 10\), \(\mu_0 = 8\) and \(\Sigma_0 = 1\).
Your figure should – modulo randomness – look something like this
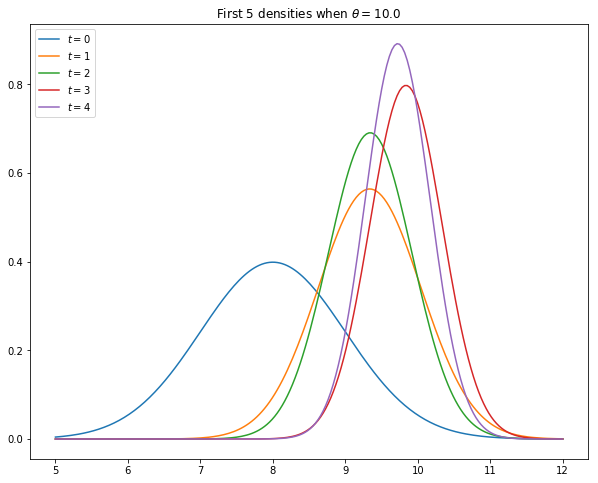
Solution
Here is one solution:
# Parameters
θ = 10 # Constant value of state X_t
A, C, G, H = 1, 0, 1, 1
ss = LinearStateSpace(A, C, G, H, mu_0=θ)
# Set prior, initialize kalman filter
μ_0, Σ_0 = 8, 1
kalman = Kalman(ss, μ_0, Σ_0)
# Draw observations of y from state space model
N = 5
x, y = ss.simulate(N)
y = y.flatten()
# Set up plot
fig, ax = plt.subplots()
xgrid = np.linspace(θ - 5, θ + 2, 200)
for i in range(N):
# Record the current predicted mean and variance
m, v = kalman.x_hat.item(), kalman.Sigma.item()
# Plot, update filter
ax.plot(xgrid, norm.pdf(xgrid, loc=m, scale=np.sqrt(v)), label=f'$t={i}$')
kalman.update(y[i])
ax.set_title(f'First {N} densities when $\\theta = {θ:.1f}$')
ax.legend(loc='upper left')
plt.show()
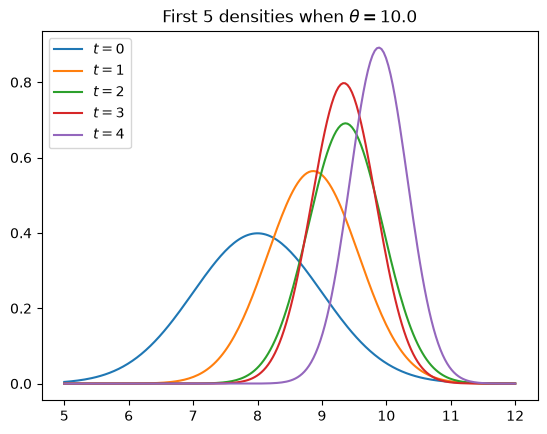
Exercise 45.2
The preceding figure gives some support to the idea that probability mass converges to \(\theta\).
To get a better idea, choose a small \(\epsilon > 0\) and calculate the error
for \(t = 0, 1, 2, \ldots, T\).
Plot \(z_t\) against \(t\), setting \(\epsilon = 0.1\) and \(T = 600\).
Solution
Here is one solution:
ϵ = 0.1
θ = 10 # Constant value of state X_t
A, C, G, H = 1, 0, 1, 1
ss = LinearStateSpace(A, C, G, H, mu_0=θ)
μ_0, Σ_0 = 8, 1
kalman = Kalman(ss, μ_0, Σ_0)
T = 600
z = np.empty(T)
x, y = ss.simulate(T)
y = y.flatten()
for t in range(T):
# Record the current predicted mean and variance and plot their densities
m, v = kalman.x_hat.item(), kalman.Sigma.item()
f = lambda x: norm.pdf(x, loc=m, scale=np.sqrt(v))
integral, error = quad(f, θ - ϵ, θ + ϵ)
z[t] = 1 - integral
kalman.update(y[t])
fig, ax = plt.subplots()
ax.set_ylim(0, 1)
ax.set_xlim(0, T)
ax.plot(range(T), z)
ax.fill_between(range(T), np.zeros(T), z, color="blue", alpha=0.2)
plt.show()
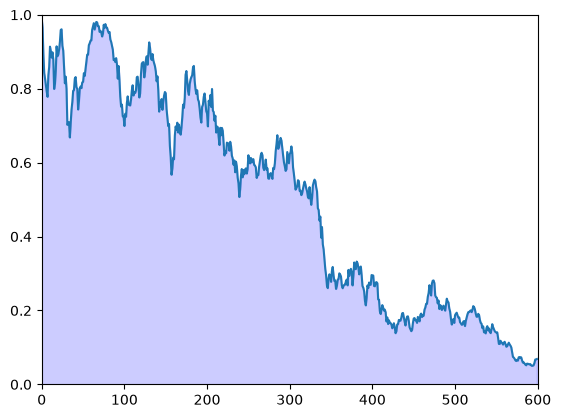
Exercise 45.3
As discussed above, if the shock sequence \(\{W_t\}\) is not degenerate, then it is not in general possible to predict \(X_t\) without error at time \(t-1\) (and this would be the case even if we could observe \(X_{t-1}\)).
Let’s now compare the prediction \(\mu_t\) made by the Kalman filter against a competitor who is allowed to observe \(X_{t-1}\).
This competitor will use the conditional expectation \(\mathbb E[ X_t \,|\, X_{t-1}]\), which in this case is \(A X_{t-1}\).
The conditional expectation is known to be the optimal prediction method in terms of minimizing mean squared error.
(More precisely, the minimizer of \(\mathbb E \, \| X_t - g(X_{t-1}) \|^2\) with respect to \(g\) is \(g^*(X_{t-1}) := \mathbb E[ X_t \,|\, X_{t-1}]\))
Thus we are comparing the Kalman filter against a competitor who has more information (in the sense of being able to observe the latent state) and behaves optimally in terms of minimizing squared error.
Our horse race will be assessed in terms of realized squared error.
In particular, your task is to generate a graph plotting simulated realizations of both \(\| X_t - A X_{t-1} \|^2\) and \(\| X_t - \mu_t \|^2\) against \(t\) for \(t = 1, \ldots, 49\).
In the code below, x[:, t] is the realized value of \(X_t\) along the simulated path.
For the parameters, set \(G = I, R = 0.5 I\) and \(Q = 0.3 I\), where \(I\) is the \(2 \times 2\) identity.
Set
To initialize the prior density, set
and \(\mu_0 = (8, 8)\).
Finally, set the realized initial state to \(x_0 = (0, 0)\).
Solution
Here is one solution:
# Define A, C, G, H
G = np.identity(2)
H = np.sqrt(0.5) * np.identity(2)
A = [[0.5, 0.4],
[0.6, 0.3]]
C = np.sqrt(0.3) * np.identity(2)
# Set up state space mode, initial value x_0 set to zero
ss = LinearStateSpace(A, C, G, H, mu_0 = np.zeros(2))
# Define the prior density
Σ = [[0.9, 0.3],
[0.3, 0.9]]
Σ = np.array(Σ)
μ = np.array([8, 8])
# Initialize the Kalman filter
kn = Kalman(ss, μ, Σ)
# Print eigenvalues of A
print("Eigenvalues of A:")
print(eigvals(A))
# Print stationary Σ
S, K = kn.stationary_values()
print("Stationary prediction error variance:")
print(S)
# Generate the plot
T = 50
x, y = ss.simulate(T)
e1 = np.empty(T-1)
e2 = np.empty(T-1)
for t in range(1, T):
kn.update(y[:, t-1])
diff1 = x[:, t] - kn.x_hat.flatten()
diff2 = x[:, t] - A @ x[:, t-1]
e1[t-1] = diff1 @ diff1
e2[t-1] = diff2 @ diff2
fig, ax = plt.subplots()
ax.plot(range(1, T), e1, 'k-', lw=2, alpha=0.6,
label='Kalman filter error')
ax.plot(range(1, T), e2, 'g-', lw=2, alpha=0.6,
label='Conditional expectation error')
ax.legend()
plt.show()
Eigenvalues of A:
[ 0.9+0.j -0.1+0.j]
Stationary prediction error variance:
[[0.40329108 0.1050718 ]
[0.1050718 0.41061709]]
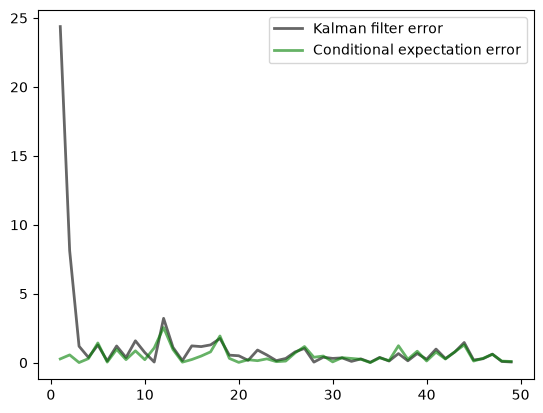
Observe how, after an initial learning period, the Kalman filter performs quite well, even relative to the competitor who predicts optimally with knowledge of the latent state.
Exercise 45.4
Try varying the coefficient \(0.3\) in \(Q = 0.3 I\) up and down.
Observe how the diagonal values in the stationary solution \(\Sigma\) (see (45.10)) increase and decrease in line with this coefficient.
The interpretation is that more randomness in the law of motion for \(X_t\) causes more (permanent) uncertainty in prediction.