40. Linear State Space Models#
“We may regard the present state of the universe as the effect of its past and the cause of its future” – Marquis de Laplace
In addition to what’s in Anaconda, this lecture will need the following libraries:
!pip install quantecon
40.1. Overview#
This lecture introduces the linear state space dynamic system.
The linear state space system is a generalization of the scalar AR(1) process we studied before.
This model is a workhorse that carries a powerful theory of prediction.
Its many applications include:
representing dynamics of higher-order linear systems
predicting the position of a system \(j\) steps into the future
predicting a geometric sum of future values of a variable like
non-financial income
dividends on a stock
the money supply
a government deficit or surplus, etc.
key ingredient of useful models
Friedman’s permanent income model of consumption smoothing.
Barro’s model of smoothing total tax collections.
Rational expectations version of Cagan’s model of hyperinflation.
Sargent and Wallace’s “unpleasant monetarist arithmetic,” etc.
Let’s start with some imports:
import matplotlib.pyplot as plt
import numpy as np
from quantecon import LinearStateSpace
from scipy.stats import norm
import random
40.2. The Linear State Space Model#
The objects in play are:
An \(n \times 1\) vector \(x_t\) denoting the state at time \(t = 0, 1, 2, \ldots\).
An IID sequence of \(m \times 1\) random vectors \(w_t \sim N(0,I)\).
A \(k \times 1\) vector \(y_t\) of observations at time \(t = 0, 1, 2, \ldots\).
An \(n \times n\) matrix \(A\) called the transition matrix.
An \(n \times m\) matrix \(C\) called the volatility matrix.
A \(k \times n\) matrix \(G\) sometimes called the output matrix.
Here is the linear state-space system
40.2.1. Primitives#
The primitives of the model are
the matrices \(A, C, G\)
shock distribution, which we have specialized to \(N(0,I)\)
the distribution of the initial condition \(x_0\), which we have set to \(N(\mu_0, \Sigma_0)\)
Given \(A, C, G\) and draws of \(x_0\) and \(w_1, w_2, \ldots\), the model (40.1) pins down the values of the sequences \(\{x_t\}\) and \(\{y_t\}\).
Even without these draws, the primitives 1–3 pin down the probability distributions of \(\{x_t\}\) and \(\{y_t\}\).
Later we’ll see how to compute these distributions and their moments.
40.2.1.1. Martingale Difference Shocks#
We’ve made the common assumption that the shocks are independent standardized normal vectors.
But some of what we say will be valid under the assumption that \(\{w_{t+1}\}\) is a martingale difference sequence.
A martingale difference sequence is a sequence that is zero mean when conditioned on past information.
In the present case, since \(\{x_t\}\) is our state sequence, this means that it satisfies
This is a weaker condition than that \(\{w_t\}\) is IID with \(w_{t+1} \sim N(0,I)\).
40.2.2. Examples#
By appropriate choice of the primitives, a variety of dynamics can be represented in terms of the linear state space model.
The following examples help to highlight this point.
They also illustrate the wise dictum finding the state is an art.
40.2.2.1. Second-order Difference Equation#
Let \(\{y_t\}\) be a deterministic sequence that satisfies
To map (40.2) into our state space system (40.1), we set
You can confirm that under these definitions, (40.1) and (40.2) agree.
The next figure shows the dynamics of this process when \(\phi_0 = 1.1, \phi_1=0.8, \phi_2 = -0.8, y_0 = y_{-1} = 1\).
def plot_lss(A,
C,
G,
n=3,
ts_length=50):
ar = LinearStateSpace(A, C, G, mu_0=np.ones(n))
x, y = ar.simulate(ts_length)
fig, ax = plt.subplots()
y = y.flatten()
ax.plot(y, 'b-', lw=2, alpha=0.7)
ax.grid()
ax.set_xlabel('time', fontsize=12)
ax.set_ylabel('$y_t$', fontsize=12)
plt.show()
ϕ_0, ϕ_1, ϕ_2 = 1.1, 0.8, -0.8
A = [[1, 0, 0 ],
[ϕ_0, ϕ_1, ϕ_2],
[0, 1, 0 ]]
C = np.zeros((3, 1))
G = [0, 1, 0]
plot_lss(A, C, G)
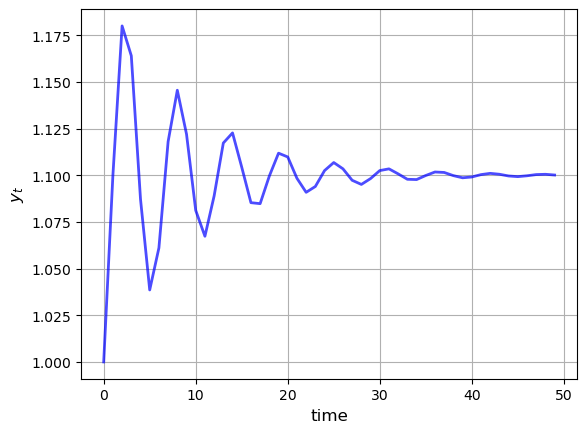
Later you’ll be asked to recreate this figure.
40.2.2.2. Univariate Autoregressive Processes#
We can use (40.1) to represent the model
where \(\{w_t\}\) is IID and standard normal.
To put this in the linear state space format we take \(x_t = \begin{bmatrix} y_t & y_{t-1} & y_{t-2} & y_{t-3} \end{bmatrix}'\) and
The matrix \(A\) has the form of the companion matrix to the vector \(\begin{bmatrix}\phi_1 & \phi_2 & \phi_3 & \phi_4 \end{bmatrix}\).
The next figure shows the dynamics of this process when
ϕ_1, ϕ_2, ϕ_3, ϕ_4 = 0.5, -0.2, 0, 0.5
σ = 0.2
A_1 = [[ϕ_1, ϕ_2, ϕ_3, ϕ_4],
[1, 0, 0, 0 ],
[0, 1, 0, 0 ],
[0, 0, 1, 0 ]]
C_1 = [[σ],
[0],
[0],
[0]]
G_1 = [1, 0, 0, 0]
plot_lss(A_1, C_1, G_1, n=4, ts_length=200)
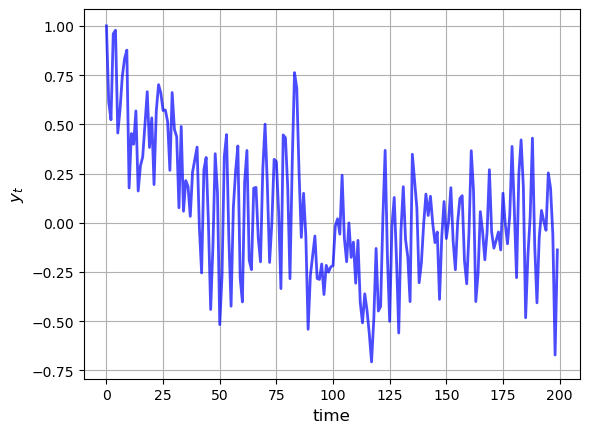
40.2.2.3. Vector Autoregressions#
Now suppose that
\(y_t\) is a \(k \times 1\) vector
\(\phi_j\) is a \(k \times k\) matrix and
\(w_t\) is \(k \times 1\)
Then (40.3) is termed a vector autoregression.
To map this into (40.1), we set
where \(I\) is the \(k \times k\) identity matrix and \(\sigma\) is a \(k \times k\) matrix.
40.2.2.4. Seasonals#
We can use (40.1) to represent
the deterministic seasonal \(y_t = y_{t-4}\)
the indeterministic seasonal \(y_t = \phi_4 y_{t-4} + w_t\)
In fact, both are special cases of (40.3).
With the deterministic seasonal, the transition matrix becomes
It is easy to check that \(A^4 = I\), which implies that \(x_t\) is strictly periodic with period 4:[1]
Such an \(x_t\) process can be used to model deterministic seasonals in quarterly time series.
The indeterministic seasonal produces recurrent, but aperiodic, seasonal fluctuations.
40.2.2.5. Time Trends#
The model \(y_t = a t + b\) is known as a linear time trend.
We can represent this model in the linear state space form by taking
and starting at initial condition \(x_0 = \begin{bmatrix} 0 & 1\end{bmatrix}'\).
In fact, it’s possible to use the state-space system to represent polynomial trends of any order.
For instance, we can represent the model \(y_t = a t^2 + bt + c\) in the linear state space form by taking
and starting at initial condition \(x_0 = \begin{bmatrix} 0 & 0 & 1 \end{bmatrix}'\).
It follows that
Then \(x_t^\prime = \begin{bmatrix} t(t-1)/2 &t & 1 \end{bmatrix}\). You can now confirm that \(y_t = G x_t\) has the correct form.
40.2.3. Moving Average Representations#
A nonrecursive expression for \(x_t\) as a function of \(x_0, w_1, w_2, \ldots, w_t\) can be found by using (40.1) repeatedly to obtain
Representation (40.5) is a moving average representation.
It expresses \(\{x_t\}\) as a linear function of
current and past values of the process \(\{w_t\}\) and
the initial condition \(x_0\)
As an example of a moving average representation, let the model be
You will be able to show that \(A^t = \begin{bmatrix} 1 & t \cr 0 & 1 \end{bmatrix}\) and \(A^j C = \begin{bmatrix} 1 & 0 \end{bmatrix}'\).
Substituting into the moving average representation (40.5), we obtain
where \(x_{1t}\) is the first entry of \(x_t\).
The first term on the right is a cumulated sum of martingale differences and is therefore a martingale.
The second term is a translated linear function of time.
For this reason, \(x_{1t}\) is called a martingale with drift.
40.3. Distributions and Moments#
40.3.1. Unconditional Moments#
Using (40.1), it’s easy to obtain expressions for the (unconditional) means of \(x_t\) and \(y_t\).
We’ll explain what unconditional and conditional mean soon.
Letting \(\mu_t := \mathbb{E} [x_t]\) and using linearity of expectations, we find that
Here \(\mu_0\) is a primitive given in (40.1).
The variance-covariance matrix of \(x_t\) is \(\Sigma_t := \mathbb{E} [ (x_t - \mu_t) (x_t - \mu_t)']\).
Using \(x_{t+1} - \mu_{t+1} = A (x_t - \mu_t) + C w_{t+1}\), we can determine this matrix recursively via
As with \(\mu_0\), the matrix \(\Sigma_0\) is a primitive given in (40.1).
As a matter of terminology, we will sometimes call
\(\mu_t\) the unconditional mean of \(x_t\)
\(\Sigma_t\) the unconditional variance-covariance matrix of \(x_t\)
This is to distinguish \(\mu_t\) and \(\Sigma_t\) from related objects that use conditioning information, to be defined below.
However, you should be aware that these “unconditional” moments do depend on the initial distribution \(N(\mu_0, \Sigma_0)\).
40.3.1.1. Moments of the Observables#
Using linearity of expectations again we have
The variance-covariance matrix of \(y_t\) is easily shown to be
40.3.2. Distributions#
In general, knowing the mean and variance-covariance matrix of a random vector is not quite as good as knowing the full distribution.
However, there are some situations where these moments alone tell us all we need to know.
These are situations in which the mean vector and covariance matrix are all of the parameters that pin down the population distribution.
One such situation is when the vector in question is Gaussian (i.e., normally distributed).
This is the case here, given
our Gaussian assumptions on the primitives
the fact that normality is preserved under linear operations
In fact, it’s well-known that
In particular, given our Gaussian assumptions on the primitives and the linearity of (40.1) we can see immediately that both \(x_t\) and \(y_t\) are Gaussian for all \(t \geq 0\) [2].
Since \(x_t\) is Gaussian, to find the distribution, all we need to do is find its mean and variance-covariance matrix.
But in fact we’ve already done this, in (40.6) and (40.7).
Letting \(\mu_t\) and \(\Sigma_t\) be as defined by these equations, we have
By similar reasoning combined with (40.8) and (40.9),
40.3.3. Ensemble Interpretations#
How should we interpret the distributions defined by (40.11)–(40.12)?
Intuitively, the probabilities in a distribution correspond to relative frequencies in a large population drawn from that distribution.
Let’s apply this idea to our setting, focusing on the distribution of \(y_T\) for fixed \(T\).
We can generate independent draws of \(y_T\) by repeatedly simulating the evolution of the system up to time \(T\), using an independent set of shocks each time.
The next figure shows 20 simulations, producing 20 time series for \(\{y_t\}\), and hence 20 draws of \(y_T\).
The system in question is the univariate autoregressive model (40.3).
The values of \(y_T\) are represented by black dots in the left-hand figure
def cross_section_plot(A,
C,
G,
T=20, # Set the time
ymin=-0.8,
ymax=1.25,
sample_size = 20, # 20 observations/simulations
n=4): # The number of dimensions for the initial x0
ar = LinearStateSpace(A, C, G, mu_0=np.ones(n))
fig, axes = plt.subplots(1, 2, figsize=(16, 5))
for ax in axes:
ax.grid(alpha=0.4)
ax.set_ylim(ymin, ymax)
ax = axes[0]
ax.set_ylim(ymin, ymax)
ax.set_ylabel('$y_t$', fontsize=12)
ax.set_xlabel('time', fontsize=12)
ax.vlines((T,), -1.5, 1.5)
ax.set_xticks((T,))
ax.set_xticklabels(('$T$',))
sample = []
for i in range(sample_size):
rcolor = random.choice(('c', 'g', 'b', 'k'))
x, y = ar.simulate(ts_length=T+15)
y = y.flatten()
ax.plot(y, color=rcolor, lw=1, alpha=0.5)
ax.plot((T,), (y[T],), 'ko', alpha=0.5)
sample.append(y[T])
y = y.flatten()
axes[1].set_ylim(ymin, ymax)
axes[1].set_ylabel('$y_t$', fontsize=12)
axes[1].set_xlabel('relative frequency', fontsize=12)
axes[1].hist(sample, bins=16, density=True, orientation='horizontal', alpha=0.5)
plt.show()
ϕ_1, ϕ_2, ϕ_3, ϕ_4 = 0.5, -0.2, 0, 0.5
σ = 0.1
A_2 = [[ϕ_1, ϕ_2, ϕ_3, ϕ_4],
[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0]]
C_2 = [[σ], [0], [0], [0]]
G_2 = [1, 0, 0, 0]
cross_section_plot(A_2, C_2, G_2)
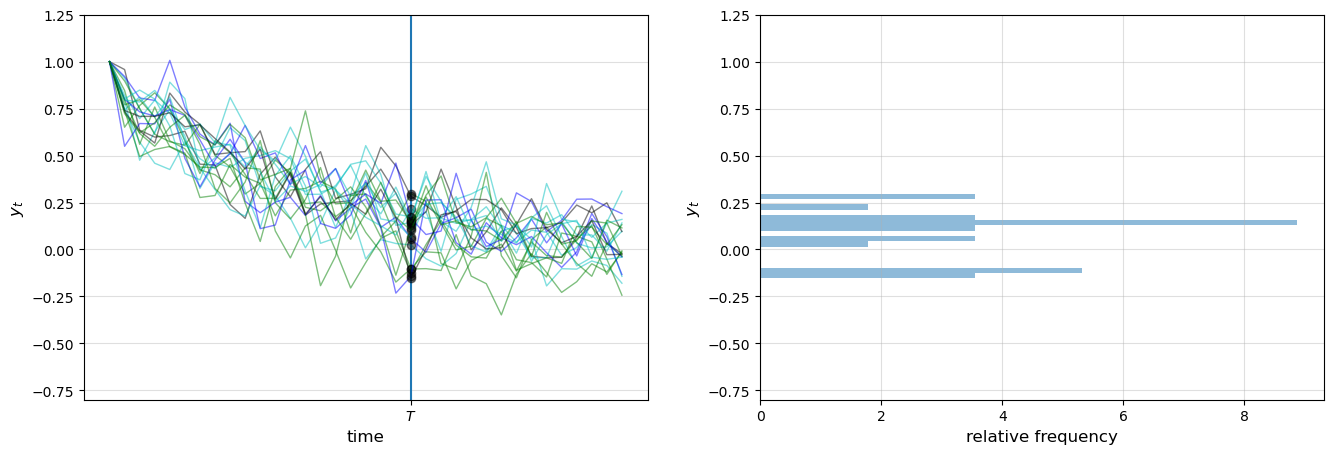
In the right-hand figure, these values are converted into a rotated histogram that shows relative frequencies from our sample of 20 \(y_T\)’s.
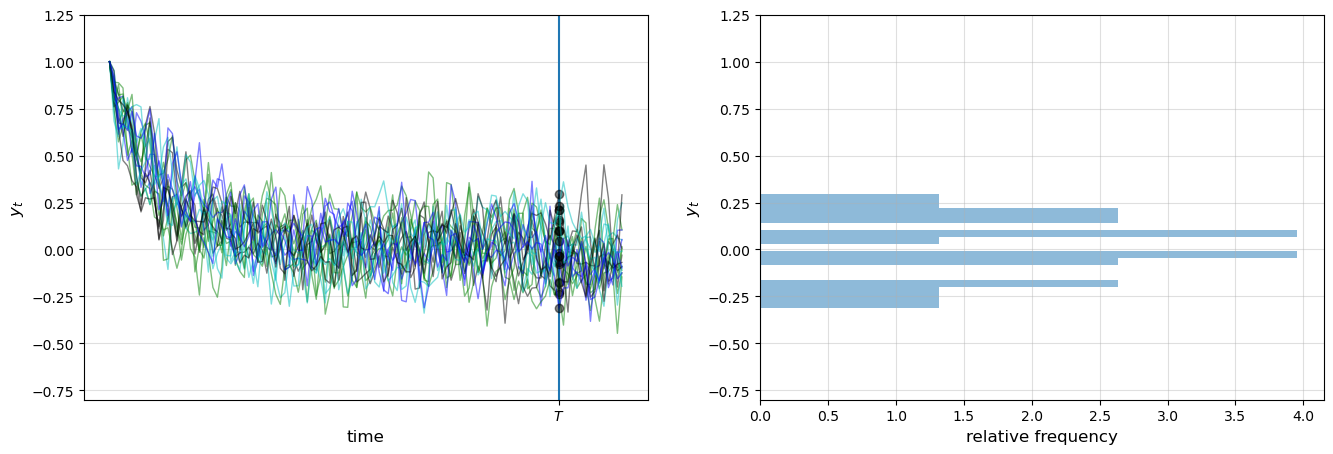
Here is another figure, this time with 100 observations
t = 100
cross_section_plot(A_2, C_2, G_2, T=t)
Let’s now try with 500,000 observations, showing only the histogram (without rotation)
T = 100
ymin=-0.8
ymax=1.25
sample_size = 500_000
ar = LinearStateSpace(A_2, C_2, G_2, mu_0=np.ones(4))
fig, ax = plt.subplots()
x, y = ar.simulate(sample_size)
mu_x, mu_y, Sigma_x, Sigma_y, Sigma_yx = ar.stationary_distributions()
f_y = norm(loc=float(mu_y.item()), scale=float(np.sqrt(Sigma_y.item())))
y = y.flatten()
ygrid = np.linspace(ymin, ymax, 150)
ax.hist(y, bins=50, density=True, alpha=0.4)
ax.plot(ygrid, f_y.pdf(ygrid), 'k-', lw=2, alpha=0.8, label='true density')
ax.set_xlim(ymin, ymax)
ax.set_xlabel('$y_t$', fontsize=12)
ax.set_ylabel('relative frequency', fontsize=12)
ax.legend(fontsize=12)
plt.show()
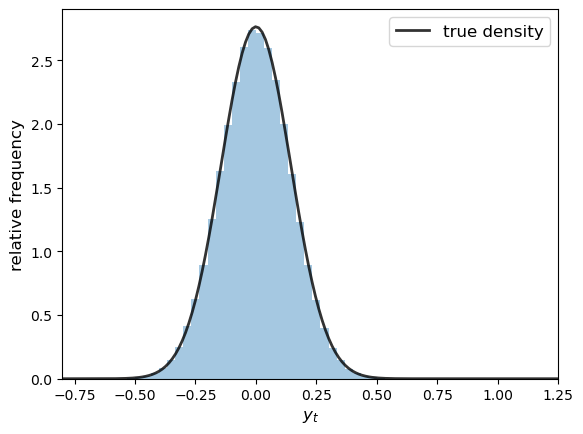
The black line is the population density of \(y_T\) calculated from (40.12).
The histogram and population distribution are close, as expected.
By looking at the figures and experimenting with parameters, you will gain a feel for how the population distribution depends on the model primitives listed above, as intermediated by the distribution’s parameters.
40.3.3.1. Ensemble Means#
In the preceding figure, we approximated the population distribution of \(y_T\) by
generating \(I\) sample paths (i.e., time series) where \(I\) is a large number
recording each observation \(y^i_T\)
histogramming this sample
Just as the histogram approximates the population distribution, the ensemble or cross-sectional average
approximates the expectation \(\mathbb{E} [y_T] = G \mu_T\) (as implied by the law of large numbers).
Here’s a simulation comparing the ensemble averages and population means at time points \(t=0,\ldots,50\).
The parameters are the same as for the preceding figures, and the sample size is relatively small (\(I=20\)).
I = 20
T = 50
ymin = -0.5
ymax = 1.15
ar = LinearStateSpace(A_2, C_2, G_2, mu_0=np.ones(4))
fig, ax = plt.subplots()
ensemble_mean = np.zeros(T)
for i in range(I):
x, y = ar.simulate(ts_length=T)
y = y.flatten()
ax.plot(y, 'c-', lw=0.8, alpha=0.5)
ensemble_mean = ensemble_mean + y
ensemble_mean = ensemble_mean / I
ax.plot(ensemble_mean, color='b', lw=2, alpha=0.8, label='$\\bar y_t$')
m = ar.moment_sequence()
population_means = []
for t in range(T):
μ_x, μ_y, Σ_x, Σ_y = next(m)
population_means.append(float(μ_y.item()))
ax.plot(population_means, color='g', lw=2, alpha=0.8, label=r'$G\mu_t$')
ax.set_ylim(ymin, ymax)
ax.set_xlabel('time', fontsize=12)
ax.set_ylabel('$y_t$', fontsize=12)
ax.legend(ncol=2)
plt.show()
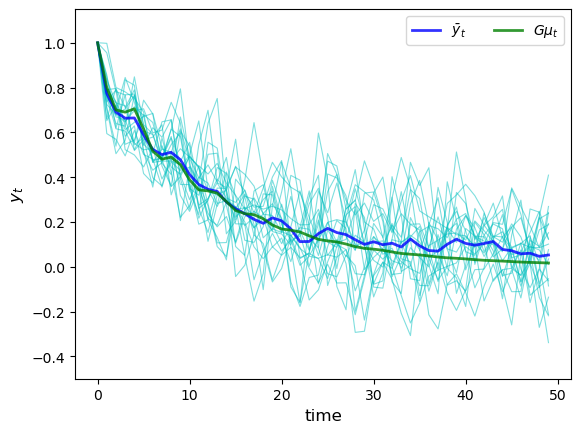
The ensemble mean for \(x_t\) is
The limit \(\mu_T\) is a “long-run average”.
(By long-run average we mean the average for an infinite (\(I = \infty\)) number of sample \(x_T\)’s)
Another application of the law of large numbers assures us that
40.3.4. Joint Distributions#
In the preceding discussion, we looked at the distributions of \(x_t\) and \(y_t\) in isolation.
This gives us useful information but doesn’t allow us to answer questions like
what’s the probability that \(x_t \geq 0\) for all \(t\)?
what’s the probability that the process \(\{y_t\}\) exceeds some value \(a\) before falling below \(b\)?
etc., etc.
Such questions concern the joint distributions of these sequences.
To compute the joint distribution of \(x_0, x_1, \ldots, x_T\), recall that joint and conditional densities are linked by the rule
From this rule we get \(p(x_0, x_1) = p(x_1 \,|\, x_0) p(x_0)\).
The Markov property \(p(x_t \,|\, x_{t-1}, \ldots, x_0) = p(x_t \,|\, x_{t-1})\) and repeated applications of the preceding rule lead us to
The marginal \(p(x_0)\) is just the primitive \(N(\mu_0, \Sigma_0)\).
In view of (40.1), the conditional densities are
40.3.4.1. Autocovariance Functions#
An important object related to the joint distribution is the autocovariance function
Elementary calculations show that
Notice that \(\Sigma_{t+j,t}\) in general depends on both \(j\), the gap between the two dates, and \(t\), the earlier date.
40.4. Stationarity and Ergodicity#
Stationarity and ergodicity are two properties that, when they hold, greatly aid analysis of linear state space models.
Let’s start with the intuition.
40.4.1. Visualizing Stability#
Let’s look at some more time series from the same model that we analyzed above.
This picture shows cross-sectional distributions for \(y\) at times \(T, T', T''\)
def cross_plot(A,
C,
G,
steady_state='False',
T0 = 10,
T1 = 50,
T2 = 75,
T4 = 100):
ar = LinearStateSpace(A, C, G, mu_0=np.ones(4))
if steady_state == 'True':
μ_x, μ_y, Σ_x, Σ_y, Σ_yx = ar.stationary_distributions()
ar_state = LinearStateSpace(A, C, G, mu_0=μ_x, Sigma_0=Σ_x)
ymin, ymax = -0.6, 0.6
fig, ax = plt.subplots()
ax.grid(alpha=0.4)
ax.set_ylim(ymin, ymax)
ax.set_ylabel('$y_t$', fontsize=12)
ax.set_xlabel('$time$', fontsize=12)
ax.vlines((T0, T1, T2), -1.5, 1.5)
ax.set_xticks((T0, T1, T2))
ax.set_xticklabels(("$T$", "$T'$", "$T''$"), fontsize=12)
for i in range(80):
rcolor = random.choice(('c', 'g', 'b'))
if steady_state == 'True':
x, y = ar_state.simulate(ts_length=T4)
else:
x, y = ar.simulate(ts_length=T4)
y = y.flatten()
ax.plot(y, color=rcolor, lw=0.8, alpha=0.5)
ax.plot((T0, T1, T2), (y[T0], y[T1], y[T2],), 'ko', alpha=0.5)
plt.show()
cross_plot(A_2, C_2, G_2)
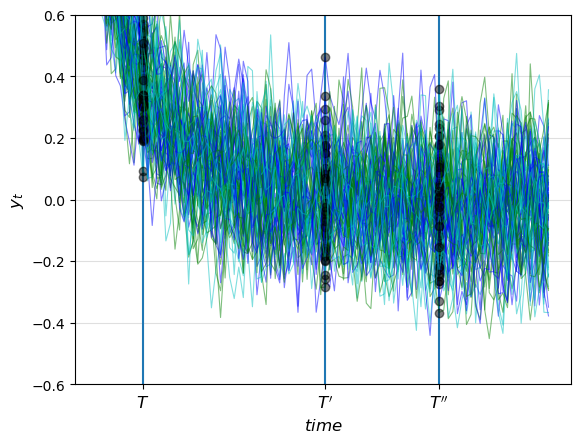
Note how the time series “settle down” in the sense that the distributions at \(T'\) and \(T''\) are relatively similar to each other — but unlike the distribution at \(T\).
Apparently, the distributions of \(y_t\) converge to a fixed long-run distribution as \(t \to \infty\).
When such a distribution exists it is called a stationary distribution.
40.4.2. Stationary Distributions#
In our setting, a distribution \(\psi_{\infty}\) is said to be stationary for \(x_t\) if
Since
in the present case, all distributions are Gaussian
a Gaussian distribution is pinned down by its mean and variance-covariance matrix
we can restate the definition as follows: \(\psi_{\infty}\) is stationary for \(x_t\) if
where \(\mu_{\infty}\) and \(\Sigma_{\infty}\) are fixed points of (40.6) and (40.7) respectively.
40.4.3. Covariance Stationary Processes#
Let’s see what happens to the preceding figure if we start \(x_0\) at the stationary distribution.
cross_plot(A_2, C_2, G_2, steady_state='True')
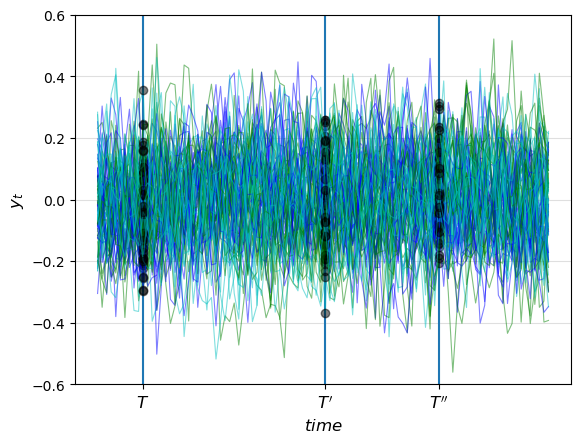
Now the differences in the observed distributions at \(T, T'\) and \(T''\) come entirely from random fluctuations due to the finite sample size.
By
our choosing \(x_0 \sim N(\mu_{\infty}, \Sigma_{\infty})\)
the definitions of \(\mu_{\infty}\) and \(\Sigma_{\infty}\) as fixed points of (40.6) and (40.7) respectively
we’ve ensured that
Moreover, in view of (40.14), the autocovariance function takes the form \(\Sigma_{t+j,t} = A^j \Sigma_\infty\), which depends on \(j\) but not on \(t\).
This motivates the following definition.
A process \(\{x_t\}\) is said to be covariance stationary if
both \(\mu_t\) and \(\Sigma_t\) are constant in \(t\)
\(\Sigma_{t+j,t}\) depends on the time gap \(j\) but not on time \(t\)
In our setting, \(\{x_t\}\) will be covariance stationary if \(\mu_0, \Sigma_0, A, C\) assume values that imply that none of \(\mu_t, \Sigma_t, \Sigma_{t+j,t}\) depends on \(t\).
40.4.4. Conditions for Stationarity#
40.4.4.1. The Globally Stable Case#
The difference equation \(\mu_{t+1} = A \mu_t\) is known to have unique fixed point \(\mu_{\infty} = 0\) if all eigenvalues of \(A\) have moduli strictly less than unity.
That is, if (np.absolute(np.linalg.eigvals(A)) < 1).all() == True.
The difference equation (40.7) also has a unique fixed point in this case, and, moreover
regardless of the initial conditions \(\mu_0\) and \(\Sigma_0\).
This is the globally stable case — see these notes for more a theoretical treatment.
However, global stability is more than we need for stationary solutions, and often more than we want.
To illustrate, consider our second order difference equation example.
Here the state is \(x_t = \begin{bmatrix} 1 & y_t & y_{t-1} \end{bmatrix}'\).
Because of the constant first component in the state vector, we will never have \(\mu_t \to 0\).
How can we find stationary solutions that respect a constant state component?
40.4.4.2. Processes with a Constant State Component#
To investigate such a process, suppose that \(A\) and \(C\) take the form
where
\(A_1\) is an \((n-1) \times (n-1)\) matrix
\(a\) is an \((n-1) \times 1\) column vector
Let \(x_t = \begin{bmatrix} x_{1t}' & 1 \end{bmatrix}'\) where \(x_{1t}\) is \((n-1) \times 1\).
It follows that
Let \(\mu_{1t} = \mathbb{E} [x_{1t}]\) and take expectations on both sides of this expression to get
Assume now that the moduli of the eigenvalues of \(A_1\) are all strictly less than one.
Then (40.15) has a unique stationary solution, namely,
The stationary value of \(\mu_t\) itself is then \(\mu_\infty := \begin{bmatrix} \mu_{1\infty}' & 1 \end{bmatrix}'\).
The stationary values of \(\Sigma_t\) and \(\Sigma_{t+j,t}\) satisfy
Notice that here \(\Sigma_{t+j,t}\) depends on the time gap \(j\) but not on calendar time \(t\).
In conclusion, if
\(x_0 \sim N(\mu_{\infty}, \Sigma_{\infty})\) and
the moduli of the eigenvalues of \(A_1\) are all strictly less than unity
then the \(\{x_t\}\) process is covariance stationary, with constant state component.
Note
If the eigenvalues of \(A_1\) are less than unity in modulus, then (a) starting from any initial value, the mean and variance-covariance matrix both converge to their stationary values; and (b) iterations on (40.7) converge to the fixed point of the discrete Lyapunov equation in the first line of (40.16).
40.4.5. Ergodicity#
Let’s suppose that we’re working with a covariance stationary process.
In this case, we know that the ensemble mean will converge to \(\mu_{\infty}\) as the sample size \(I\) approaches infinity.
40.4.5.1. Averages over Time#
Ensemble averages across simulations are interesting theoretically, but in real life, we usually observe only a single realization \(\{x_t, y_t\}_{t=0}^T\).
So now let’s take a single realization and form the time-series averages
Do these time series averages converge to something interpretable in terms of our basic state-space representation?
The answer depends on something called ergodicity.
Ergodicity is the property that time series and ensemble averages coincide.
More formally, ergodicity implies that time series sample averages converge to their expectation under the stationary distribution.
In particular,
\(\frac{1}{T} \sum_{t=1}^T x_t \to \mu_{\infty}\)
\(\frac{1}{T} \sum_{t=1}^T (x_t -\bar x_T) (x_t - \bar x_T)' \to \Sigma_\infty\)
\(\frac{1}{T} \sum_{t=1}^T (x_{t+j} -\bar x_T) (x_t - \bar x_T)' \to A^j \Sigma_\infty\)
In our linear Gaussian setting, any covariance stationary process is also ergodic.
40.5. Noisy Observations#
In some settings, the observation equation \(y_t = Gx_t\) is modified to include an error term.
Often this error term represents the idea that the true state can only be observed imperfectly.
To include an error term in the observation we introduce
An IID sequence of \(\ell \times 1\) random vectors \(v_t \sim N(0,I)\).
A \(k \times \ell\) matrix \(H\).
and extend the linear state-space system to
The sequence \(\{v_t\}\) is assumed to be independent of \(\{w_t\}\).
The process \(\{x_t\}\) is not modified by noise in the observation equation and its moments, distributions and stability properties remain the same.
The unconditional moments of \(y_t\) from (40.8) and (40.9) now become
The variance-covariance matrix of \(y_t\) is easily shown to be
The distribution of \(y_t\) is therefore
40.6. Prediction#
The theory of prediction for linear state space systems is elegant and simple.
40.6.1. Forecasting Formulas – Conditional Means#
The natural way to predict variables is to use conditional distributions.
For example, the optimal forecast of \(x_{t+1}\) given information known at time \(t\) is
The right-hand side follows from \(x_{t+1} = A x_t + C w_{t+1}\) and the fact that \(w_{t+1}\) is zero mean and independent of \(x_t, x_{t-1}, \ldots, x_0\).
That \(\mathbb{E}_t [x_{t+1}] = \mathbb{E}[x_{t+1} \mid x_t]\) is an implication of \(\{x_t\}\) having the Markov property.
The one-step-ahead forecast error is
The covariance matrix of the forecast error is
More generally, we’d like to compute the \(j\)-step ahead forecasts \(\mathbb{E}_t [x_{t+j}]\) and \(\mathbb{E}_t [y_{t+j}]\).
With a bit of algebra, we obtain
In view of the IID property, current and past state values provide no information about future values of the shock.
Hence \(\mathbb{E}_t[w_{t+k}] = \mathbb{E}[w_{t+k}] = 0\).
It now follows from linearity of expectations that the \(j\)-step ahead forecast of \(x\) is
The \(j\)-step ahead forecast of \(y\) is therefore
40.6.2. Covariance of Prediction Errors#
It is useful to obtain the covariance matrix of the vector of \(j\)-step-ahead prediction errors
Evidently,
\(V_j\) defined in (40.21) can be calculated recursively via \(V_1 = CC'\) and
\(V_j\) is the conditional covariance matrix of the errors in forecasting \(x_{t+j}\), conditioned on time \(t\) information \(x_t\).
Under particular conditions, \(V_j\) converges to
Equation (40.23) is an example of a discrete Lyapunov equation in the covariance matrix \(V_\infty\).
A sufficient condition for \(V_j\) to converge is that the eigenvalues of \(A\) be strictly less than one in modulus.
Weaker sufficient conditions for convergence associate eigenvalues equaling or exceeding one in modulus with elements of \(C\) that equal \(0\).
40.7. Code#
Our preceding simulations and calculations are based on code in the file lss.py from the QuantEcon.py package.
The code implements a class for handling linear state space models (simulations, calculating moments, etc.).
One Python construct you might not be familiar with is the use of a generator function in the method moment_sequence().
Go back and read the relevant documentation if you’ve forgotten how generator functions work.
Examples of usage are given in the solutions to the exercises.
40.8. Exercises#
Exercise 40.1
In several contexts, we want to compute forecasts of geometric sums of future random variables governed by the linear state-space system (40.1).
We want the following objects
Forecast of a geometric sum of future \(x\)’s, or \(\mathbb{E}_t \left[ \sum_{j=0}^\infty \beta^j x_{t+j} \right]\).
Forecast of a geometric sum of future \(y\)’s, or \(\mathbb{E}_t \left[\sum_{j=0}^\infty \beta^j y_{t+j} \right]\).
These objects are important components of some famous and interesting dynamic models.
For example,
if \(\{y_t\}\) is a stream of dividends, then \(\mathbb{E} \left[\sum_{j=0}^\infty \beta^j y_{t+j} | x_t \right]\) is a model of a stock price
if \(\{y_t\}\) is the money supply, then \(\mathbb{E} \left[\sum_{j=0}^\infty \beta^j y_{t+j} | x_t \right]\) is a model of the price level
Show that:
and
what must the modulus for every eigenvalue of \(A\) be less than?
Solution
Suppose that every eigenvalue of \(A\) has modulus strictly less than \(\frac{1}{\beta}\).
It then follows that \(I + \beta A + \beta^2 A^2 + \cdots = \left[I - \beta A \right]^{-1}\).
This leads to our formulas:
Forecast of a geometric sum of future \(x\)’s
Forecast of a geometric sum of future \(y\)’s