43. Kesten Processes and Firm Dynamics#
In addition to what’s in Anaconda, this lecture will need the following libraries:
!pip install quantecon
!pip install --upgrade yfinance
43.1. Overview#
Previously we learned about linear scalar-valued stochastic processes (AR(1) models).
Now we generalize these linear models slightly by allowing the multiplicative coefficient to be stochastic.
Such processes are known as Kesten processes after German–American mathematician Harry Kesten (1931–2019)
Although simple to write down, Kesten processes are interesting for at least two reasons:
A number of significant economic processes are or can be described as Kesten processes.
Kesten processes generate interesting dynamics, including, in some cases, heavy-tailed cross-sectional distributions.
We will discuss these issues as we go along.
Let’s start with some imports:
import matplotlib.pyplot as plt
import numpy as np
import quantecon as qe
The following two lines are only added to avoid a FutureWarning caused by
compatibility issues between pandas and matplotlib.
from pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()
Additional technical background related to this lecture can be found in the monograph of [Buraczewski et al., 2016].
43.2. Kesten Processes#
A Kesten process is a stochastic process of the form
where \(\{a_t\}_{t \geq 1}\) and \(\{\eta_t\}_{t \geq 1}\) are IID sequences.
We are interested in the dynamics of \(\{X_t\}_{t \geq 0}\) when \(X_0\) is given.
We will focus on the nonnegative scalar case, where \(X_t\) takes values in \(\mathbb R_+\).
In particular, we will assume that
the initial condition \(X_0\) is nonnegative,
\(\{a_t\}_{t \geq 1}\) is a nonnegative IID stochastic process and
\(\{\eta_t\}_{t \geq 1}\) is another nonnegative IID stochastic process, independent of the first.
43.2.1. Example: GARCH Volatility#
The GARCH model is common in financial applications, where time series such as asset returns exhibit time varying volatility.
For example, consider the following plot of daily returns on the Nasdaq Composite Index for the period 1st January 2006 to 1st November 2019.
import yfinance as yf
s = yf.download('^IXIC', '2006-1-1', '2019-11-1', auto_adjust=False)['Adj Close']
r = s.pct_change()
fig, ax = plt.subplots()
ax.plot(r, alpha=0.7)
ax.set_ylabel('returns', fontsize=12)
ax.set_xlabel('date', fontsize=12)
plt.show()
[*********************100%***********************] 1 of 1 completed
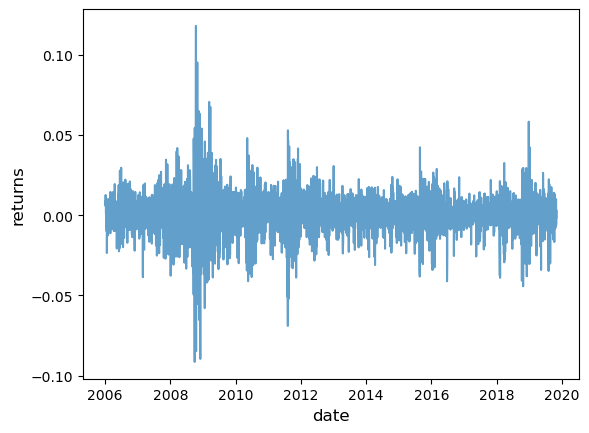
Notice how the series exhibits bursts of volatility (high variance) and then settles down again.
GARCH models can replicate this feature.
The GARCH(1, 1) volatility process takes the form
where \(\{\xi_t\}\) is IID with \(\mathbb E \xi_t^2 = 1\) and all parameters are positive.
Returns on a given asset are then modeled as
where \(\{\zeta_t\}\) is again IID and independent of \(\{\xi_t\}\).
The volatility sequence \(\{\sigma_t^2 \}\), which drives the dynamics of returns, is a Kesten process.
43.2.2. Example: Wealth Dynamics#
Suppose that a given household saves a fixed fraction \(s\) of its current wealth in every period.
The household earns labor income \(y_t\) at the start of time \(t\).
Wealth then evolves according to
where \(\{R_t\}\) is the gross rate of return on assets.
If \(\{R_t\}\) and \(\{y_t\}\) are both IID, then (43.4) is a Kesten process.
43.2.3. Stationarity#
In earlier lectures, such as the one on AR(1) processes, we introduced the notion of a stationary distribution.
In the present context, we can define a stationary distribution as follows:
The distribution \(F^*\) on \(\mathbb R\) is called stationary for the Kesten process (43.1) if
In other words, if the current state \(X_t\) has distribution \(F^*\), then so does the next period state \(X_{t+1}\).
We can write this alternatively as
The left hand side is the distribution of the next period state when the current state is drawn from \(F^*\).
The equality in (43.6) states that this distribution is unchanged.
43.2.4. Cross-Sectional Interpretation#
There is an important cross-sectional interpretation of stationary distributions, discussed previously but worth repeating here.
Suppose, for example, that we are interested in the wealth distribution — that is, the current distribution of wealth across households in a given country.
Suppose further that
the wealth of each household evolves independently according to (43.4),
\(F^*\) is a stationary distribution for this stochastic process and
there are many households.
Then \(F^*\) is a steady state for the cross-sectional wealth distribution in this country.
In other words, if \(F^*\) is the current wealth distribution then it will remain so in subsequent periods, ceteris paribus.
To see this, suppose that \(F^*\) is the current wealth distribution.
What is the fraction of households with wealth less than \(y\) next period?
To obtain this, we sum the probability that wealth is less than \(y\) tomorrow, given that current wealth is \(w\), weighted by the fraction of households with wealth \(w\).
Noting that the fraction of households with wealth in interval \(dw\) is \(F^*(dw)\), we get
By the definition of stationarity and the assumption that \(F^*\) is stationary for the wealth process, this is just \(F^*(y)\).
Hence the fraction of households with wealth in \([0, y]\) is the same next period as it is this period.
Since \(y\) was chosen arbitrarily, the distribution is unchanged.
43.2.5. Conditions for Stationarity#
The Kesten process \(X_{t+1} = a_{t+1} X_t + \eta_{t+1}\) does not always have a stationary distribution.
For example, if \(a_t \equiv \eta_t \equiv 1\) for all \(t\), then \(X_t = X_0 + t\), which diverges to infinity.
To prevent this kind of divergence, we require that \(\{a_t\}\) is strictly less than 1 most of the time.
In particular, if
then a unique stationary distribution exists on \(\mathbb R_+\).
See, for example, theorem 2.1.3 of [Buraczewski et al., 2016], which provides slightly weaker conditions.
As one application of this result, we see that the wealth process (43.4) will have a unique stationary distribution whenever labor income has finite mean and \(\mathbb E \ln R_t + \ln s < 0\).
43.3. Heavy Tails#
Under certain conditions, the stationary distribution of a Kesten process has a Pareto tail.
(See our earlier lecture on heavy-tailed distributions for background.)
This fact is significant for economics because of the prevalence of Pareto-tailed distributions.
43.3.1. The Kesten–Goldie Theorem#
To state the conditions under which the stationary distribution of a Kesten process has a Pareto tail, we first recall that a random variable is called nonarithmetic if its distribution is not concentrated on \(\{\dots, -2t, -t, 0, t, 2t, \ldots \}\) for any \(t \geq 0\).
For example, any random variable with a density is nonarithmetic.
The famous Kesten–Goldie Theorem (see, e.g., [Buraczewski et al., 2016], theorem 2.4.4) states that if
the stationarity conditions in (43.7) hold,
the random variable \(a_t\) is positive with probability one and nonarithmetic,
\(\mathbb P\{a_t x + \eta_t = x\} < 1\) for all \(x \in \mathbb R_+\) and
there exists a positive constant \(\alpha\) such that
then the stationary distribution of the Kesten process has a Pareto tail with tail index \(\alpha\).
More precisely, if \(F^*\) is the unique stationary distribution and \(X^* \sim F^*\), then
for some positive constant \(c\).
43.3.2. Intuition#
Later we will illustrate the Kesten–Goldie Theorem using rank-size plots.
Prior to doing so, we can give the following intuition for the conditions.
Two important conditions are that \(\mathbb E \ln a_t < 0\), so the model is stationary, and \(\mathbb E a_t^\alpha = 1\) for some \(\alpha > 0\).
The first condition implies that the distribution of \(a_t\) has a large amount of probability mass below 1.
The second condition implies that the distribution of \(a_t\) has at least some probability mass at or above 1.
The first condition gives us existence of the stationary condition.
The second condition means that the current state can be expanded by \(a_t\).
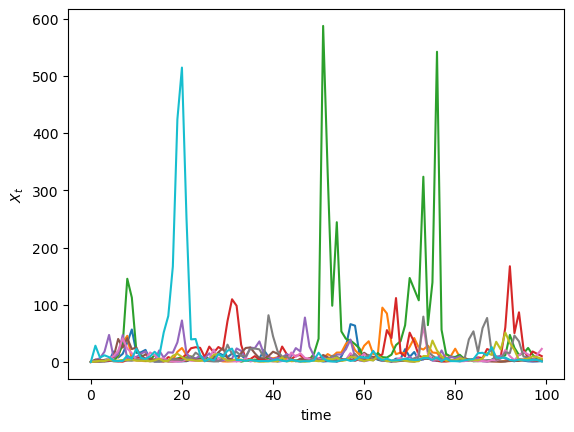
If this occurs for several concurrent periods, the effects compound each other, since \(a_t\) is multiplicative.
This leads to spikes in the time series, which fill out the extreme right hand tail of the distribution.
The spikes in the time series are visible in the following simulation, which generates of 10 paths when \(a_t\) and \(b_t\) are lognormal.
μ = -0.5
σ = 1.0
def kesten_ts(ts_length=100):
x = np.zeros(ts_length)
for t in range(ts_length-1):
a = np.exp(μ + σ * np.random.randn())
b = np.exp(np.random.randn())
x[t+1] = a * x[t] + b
return x
fig, ax = plt.subplots()
num_paths = 10
np.random.seed(12)
for i in range(num_paths):
ax.plot(kesten_ts())
ax.set(xlabel='time', ylabel='$X_t$')
plt.show()
43.4. Application: Firm Dynamics#
As noted in our lecture on heavy tails, for common measures of firm size such as revenue or employment, the US firm size distribution exhibits a Pareto tail (see, e.g., [Axtell, 2001], [Gabaix, 2016]).
Let us try to explain this rather striking fact using the Kesten–Goldie Theorem.
43.4.1. Gibrat’s Law#
It was postulated many years ago by Robert Gibrat [Gibrat, 1931] that firm size evolves according to a simple rule whereby size next period is proportional to current size.
This is now known as Gibrat’s law of proportional growth.
We can express this idea by stating that a suitably defined measure \(s_t\) of firm size obeys
for some positive IID sequence \(\{a_t\}\).
One implication of Gibrat’s law is that the growth rate of individual firms does not depend on their size.
However, over the last few decades, research contradicting Gibrat’s law has accumulated in the literature.
For example, it is commonly found that, on average,
small firms grow faster than large firms (see, e.g., [Evans, 1987] and [Hall, 1987]) and
the growth rate of small firms is more volatile than that of large firms [Dunne et al., 1989].
On the other hand, Gibrat’s law is generally found to be a reasonable approximation for large firms [Evans, 1987].
We can accommodate these empirical findings by modifying (43.8) to
where \(\{a_t\}\) and \(\{b_t\}\) are both IID and independent of each other.
In the exercises you are asked to show that (43.9) is more consistent with the empirical findings presented above than Gibrat’s law in (43.8).
43.4.2. Heavy Tails#
So what has this to do with Pareto tails?
The answer is that (43.9) is a Kesten process.
If the conditions of the Kesten–Goldie Theorem are satisfied, then the firm size distribution is predicted to have heavy tails — which is exactly what we see in the data.
In the exercises below we explore this idea further, generalizing the firm size dynamics and examining the corresponding rank-size plots.
We also try to illustrate why the Pareto tail finding is significant for quantitative analysis.
43.5. Exercises#
Exercise 43.1
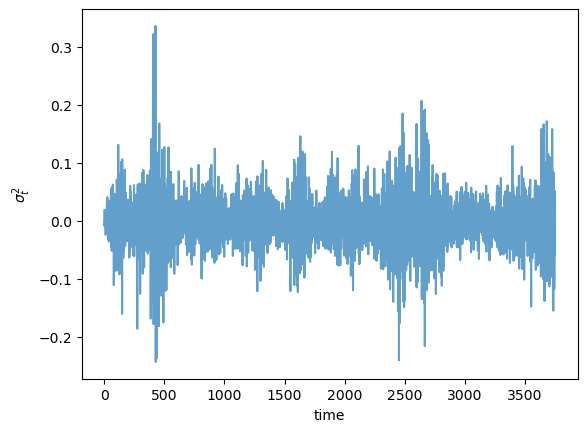
Simulate and plot 15 years of daily returns (consider each year as having 250 working days) using the GARCH(1, 1) process in (43.2)–(43.3).
Take \(\xi_t\) and \(\zeta_t\) to be independent and standard normal.
Set \(\alpha_0 = 0.00001, \alpha_1 = 0.1, \beta = 0.9\) and \(\sigma_0 = 0\).
Compare visually with the Nasdaq Composite Index returns shown above.
While the time path differs, you should see bursts of high volatility.
Solution
Here is one solution:
α_0 = 1e-5
α_1 = 0.1
β = 0.9
years = 15
days = years * 250
def garch_ts(ts_length=days):
σ2 = 0
r = np.zeros(ts_length)
for t in range(ts_length-1):
ξ = np.random.randn()
σ2 = α_0 + σ2 * (α_1 * ξ**2 + β)
r[t] = np.sqrt(σ2) * np.random.randn()
return r
fig, ax = plt.subplots()
np.random.seed(12)
ax.plot(garch_ts(), alpha=0.7)
ax.set(xlabel='time', ylabel='$\\sigma_t^2$')
plt.show()
Exercise 43.2
In our discussion of firm dynamics, it was claimed that (43.9) is more consistent with the empirical literature than Gibrat’s law in (43.8).
(The empirical literature was reviewed immediately above (43.9).)
In what sense is this true (or false)?
Solution
The empirical findings are that
small firms grow faster than large firms and
the growth rate of small firms is more volatile than that of large firms.
Also, Gibrat’s law is generally found to be a reasonable approximation for large firms than for small firms
The claim is that the dynamics in (43.9) are more consistent with points 1-2 than Gibrat’s law.
To see why, we rewrite (43.9) in terms of growth dynamics:
Taking \(s_t = s\) as given, the mean and variance of firm growth are
Both of these decline with firm size \(s\), consistent with the data.
Moreover, the law of motion (43.10) clearly approaches Gibrat’s law (43.8) as \(s_t\) gets large.
Exercise 43.3
Consider an arbitrary Kesten process as given in (43.1).
Suppose that \(\{a_t\}\) is lognormal with parameters \((\mu, \sigma)\).
In other words, each \(a_t\) has the same distribution as \(\exp(\mu + \sigma Z)\) when \(Z\) is standard normal.
Suppose further that \(\mathbb E \eta_t^r < \infty\) for every \(r > 0\), as would be the case if, say, \(\eta_t\) is also lognormal.
Show that the conditions of the Kesten–Goldie theorem are satisfied if and only if \(\mu < 0\).
Obtain the value of \(\alpha\) that makes the Kesten–Goldie conditions hold.
Solution
Since \(a_t\) has a density it is nonarithmetic.
Since \(a_t\) has the same density as \(a = \exp(\mu + \sigma Z)\) when \(Z\) is standard normal, we have
and since \(\eta_t\) has finite moments of all orders, the stationarity condition holds if and only if \(\mu < 0\).
Given the properties of the lognormal distribution (which has finite moments of all orders), the only other condition in doubt is existence of a positive constant \(\alpha\) such that \(\mathbb E a_t^\alpha = 1\).
This is equivalent to the statement
Solving for \(\alpha\) gives \(\alpha = -2\mu / \sigma^2\).
Exercise 43.4
One unrealistic aspect of the firm dynamics specified in (43.9) is that it ignores entry and exit.
In any given period and in any given market, we observe significant numbers of firms entering and exiting the market.
Empirical discussion of this can be found in a famous paper by Hugo Hopenhayn [Hopenhayn, 1992].
In the same paper, Hopenhayn builds a model of entry and exit that incorporates profit maximization by firms and market clearing quantities, wages and prices.
In his model, a stationary equilibrium occurs when the number of entrants equals the number of exiting firms.
In this setting, firm dynamics can be expressed as
Here
the state variable \(s_t\) represents productivity (which is a proxy for output and hence firm size),
the IID sequence \(\{ e_t \}\) is thought of as a productivity draw for a new entrant and
the variable \(\bar s\) is a threshold value that we take as given, although it is determined endogenously in Hopenhayn’s model.
The idea behind (43.11) is that firms stay in the market as long as their productivity \(s_t\) remains at or above \(\bar s\).
In this case, their productivity updates according to (43.9).
Firms choose to exit when their productivity \(s_t\) falls below \(\bar s\).
In this case, they are replaced by a new firm with productivity \(e_{t+1}\).
What can we say about dynamics?
Although (43.11) is not a Kesten process, it does update in the same way as a Kesten process when \(s_t\) is large.
So perhaps its stationary distribution still has Pareto tails?
Your task is to investigate this question via simulation and rank-size plots.
The approach will be to
generate \(M\) draws of \(s_T\) when \(M\) and \(T\) are large and
plot the largest 1,000 of the resulting draws in a rank-size plot.
(The distribution of \(s_T\) will be close to the stationary distribution when \(T\) is large.)
In the simulation, assume that
each of \(a_t, b_t\) and \(e_t\) is lognormal,
the parameters are
μ_a = -0.5 # location parameter for a
σ_a = 0.1 # scale parameter for a
μ_b = 0.0 # location parameter for b
σ_b = 0.5 # scale parameter for b
μ_e = 0.0 # location parameter for e
σ_e = 0.5 # scale parameter for e
s_bar = 1.0 # threshold
T = 500 # sampling date
M = 1_000_000 # number of firms
s_init = 1.0 # initial condition for each firm
Solution
Here’s one solution. First we generate the observations:
from numba import jit, prange
from numpy.random import randn
@jit(parallel=True)
def generate_draws(μ_a=-0.5,
σ_a=0.1,
μ_b=0.0,
σ_b=0.5,
μ_e=0.0,
σ_e=0.5,
s_bar=1.0,
T=500,
M=1_000_000,
s_init=1.0):
draws = np.empty(M)
for m in prange(M):
s = s_init
for t in range(T):
if s < s_bar:
new_s = np.exp(μ_e + σ_e * randn())
else:
a = np.exp(μ_a + σ_a * randn())
b = np.exp(μ_b + σ_b * randn())
new_s = a * s + b
s = new_s
draws[m] = s
return draws
data = generate_draws()
Now we produce the rank-size plot:
fig, ax = plt.subplots()
rank_data, size_data = qe.rank_size(data, c=0.01)
ax.loglog(rank_data, size_data, 'o', markersize=3.0, alpha=0.5)
ax.set_xlabel("log rank")
ax.set_ylabel("log size")
plt.show()
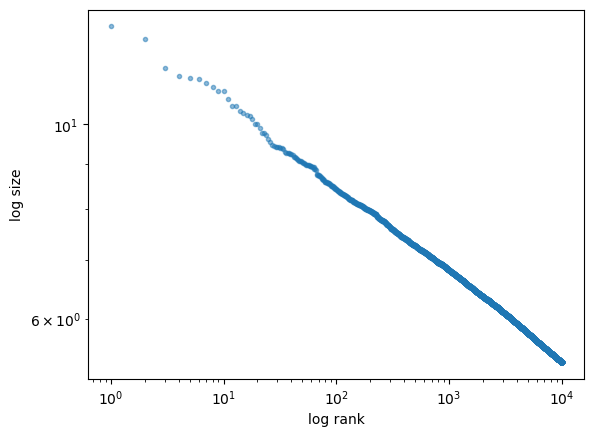
The plot produces a straight line, consistent with a Pareto tail.